
Ever since the dawn of time the storage administrators have been indoctrinated with redundancy. You have to have everything at least twice in order to maintain uptime and be able to achieve this to a level of around 99,999%. This is true in many occasions however there are exceptions when even dual fabrics (ie physically separated) share components like hosts, arrays or tapes.. If a physical issue in one fabric is impacting that shared component the performance and host IO may even impact totally unrelated equipment on another fabric and spin out of control.
So now and then I come across a case where erratic IO behaviour and performance problems occur on a multitude of hosts connected to multiple fabrics and even so many arrays. The errors seen from a fabric perspective are most often AN-1010 event entries like these:
2015/04/04-21:28:51, [AN-1010], 3377, FID 128, WARNING, sw01, Severe latency bottleneck detected at slot 0 port 3.
In 99% of all cases this particular issue is caused by one or more initiators or target causing credit depletion which then back-pressures into the fabric. (Articles around credit backpressure and frameflow can be found here , here , here and here)
A small schematic representation of a dual core-edge (which is a bad design !!) which is in use at many datacentres around the world, is shown here.
 If one of the HBA’s at the host side is observing a problem this can causes credit issues between the switch and the HBA. Obviously (as I explained in the other articles) this trickles down to other parts of that same fabric hence you can imagine that other host traffic sharing the same paths will suffer as well.
If one of the HBA’s at the host side is observing a problem this can causes credit issues between the switch and the HBA. Obviously (as I explained in the other articles) this trickles down to other parts of that same fabric hence you can imagine that other host traffic sharing the same paths will suffer as well.
 But here’s the catch. As you can see the array at the bottom obviously has a finite amount of resources. It will do it utmost best to fulfil requests from this host but if frames go missing the overall status of these IO requests are unknown to the array and therefore it will rely on internal and external timeout values to recoup these resources. In the above example lets say the host sends a write request of 24MB to LUN 1 on sector off-set 8395277. What happens in the array is that as soon as the SCSI command is received it will start allocating resources like cache slots, CPU and/or ASIC threads, internal notifications to other parts of the array in order to have these parts reserve resources like data-offloading from cache etc.. Depending on these available array resources it will send a XFER-RDY back to the host which says, “from request X you can send the first Y blocks”. If that particular XFER_RDY frame is lost somewhere in the fabric both the host and the array have no status of either side. The host doesn’t know if the SCSI command has reached the array and therefore has to wait for a timeout in order to send an abort plus the array has no idea why it takes so long for the host to start sending data. This means that both parties are in a somewhat dead-lock situation and can’t do anything with this particular request until these timeout thresholds have past. A result of this is that the allocated resources in the array cannot be freed up and thus cannot be used for other requests even if they come from a second initiator on a different fabric. (This is depicted with the blue arrows in the above picture.)
But here’s the catch. As you can see the array at the bottom obviously has a finite amount of resources. It will do it utmost best to fulfil requests from this host but if frames go missing the overall status of these IO requests are unknown to the array and therefore it will rely on internal and external timeout values to recoup these resources. In the above example lets say the host sends a write request of 24MB to LUN 1 on sector off-set 8395277. What happens in the array is that as soon as the SCSI command is received it will start allocating resources like cache slots, CPU and/or ASIC threads, internal notifications to other parts of the array in order to have these parts reserve resources like data-offloading from cache etc.. Depending on these available array resources it will send a XFER-RDY back to the host which says, “from request X you can send the first Y blocks”. If that particular XFER_RDY frame is lost somewhere in the fabric both the host and the array have no status of either side. The host doesn’t know if the SCSI command has reached the array and therefore has to wait for a timeout in order to send an abort plus the array has no idea why it takes so long for the host to start sending data. This means that both parties are in a somewhat dead-lock situation and can’t do anything with this particular request until these timeout thresholds have past. A result of this is that the allocated resources in the array cannot be freed up and thus cannot be used for other requests even if they come from a second initiator on a different fabric. (This is depicted with the blue arrows in the above picture.)
A follow-up consequence is that, due to this shortage in array resources, other hosts, which may or may not have connections in the same fabrics but are linked to that array, will also suffer from this particular problem as you can see here.
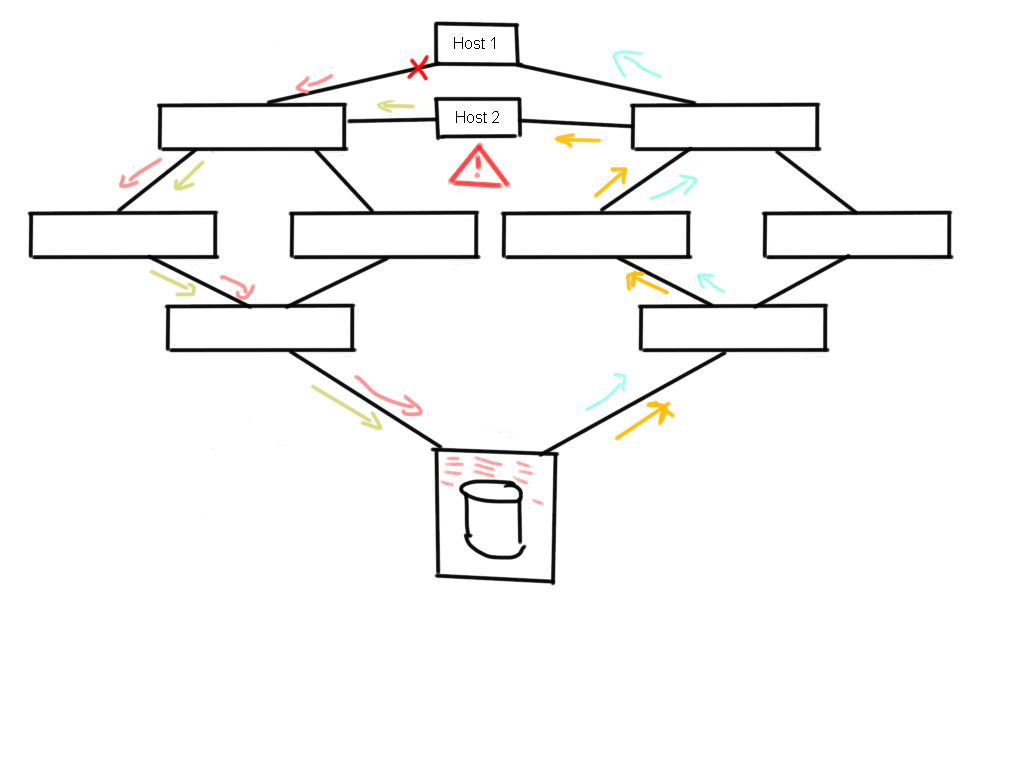 Host #1 can be using the path in the left-hand fabric and Host #2 can be using the paths in the right-hand fabric but even though they do not share the same traffic paths at that stage they both can be impacted due to lack of array resources caused by the faulty link on the Host #1 side.
Host #1 can be using the path in the left-hand fabric and Host #2 can be using the paths in the right-hand fabric but even though they do not share the same traffic paths at that stage they both can be impacted due to lack of array resources caused by the faulty link on the Host #1 side.
The problem may be exacerbated if, due to credit depletion, frames are lost in the fabric from Host #2 and therefore may increase resource usage in the array.
Environment segregation
The issue becomes even more severe if you think about the fact that above environment could be a test/dev one but for some reason the same array is used in a multi-million dollar revenue generating production fabric as below.
 Host #3 in this case is a huge Unix/VMS/”take your pick” system running several customer facing CRM modules. Even though this host doesn’t have any shared traffic paths, the lack of array resources caused by that single HBA from host #1 can and will cause performance problems on Host #3.
Host #3 in this case is a huge Unix/VMS/”take your pick” system running several customer facing CRM modules. Even though this host doesn’t have any shared traffic paths, the lack of array resources caused by that single HBA from host #1 can and will cause performance problems on Host #3.
Many of the enterprise grade arrays have capabilities to prevent these kind of circumstances like creating virtual arrays or resource partitions where external and internal resources are dedicated to a virtual instance inside that array. Bear in mind that even then some parts of the array may be shared. If you want a 100% guarantee your production environment is not a victim of any of the above scenarios make sure there is “air-space” between these environments and don’t let them share any resource.
I’ve made a plea for Fabric Watch/ MAPS with portfencing rules before (see here) and I cannot stress the importance of this feature.
ROT (and your an idiot if you don’t follow this!):
If a port observes a physical issue SHUT IT DOWN!!! No questions asked, no discussions, no excuses, no single-path host comments, no executive meetings. Nothing, Nada, Rien, Niente, 沒什麼. !!!! SHUT IT DOWN.
A port that observes physical issues will 100% certain cause issues for the attached device but, as I’ve shown in posts before, the chances it will cause further problems in fabrics is extremely close to that 100% mark. Do yourself and your business a favour, buy the necessary licenses (if any) and configure port-fencing (Brocade term) or port-guard (Cisco term). It will save you a massive headache when you run into this issue.
Hope this helps.
Kind regards,
Erwin
