Many of you have used and managed fibre-channel based storage networks over the years. It comes to no surprise that a network protocol primarily developed to handle extremely time-sensitive operations is build with extreme demand regarding hardware and software quality and clear guidelines on how these communications should proceed. It is due to this that fibre-channel has become the dominant protocol in datacenters for storage. Continue reading
Tag Archives: T11
Closing the Fibre-Channel resiliency gap – 2
So this morning I uploaded my proposal to T11 (13-348v0) in order to get the ball rolling to get it adopted in the FC-LS-3 standard. (That would be awesome). Obviously the task to get things done in a very stable protocol which is known for some serious backward compatibility is not an easy undertaking. I’ve tried (and I think I succeeded) in leaving all existing behaviour intact. This way any transition towards an environment that supports this new architecture is seamless.
The document should be download-able for everyone so any feedback is highly appreciated.
Cheers,
Erwin
Closing the Fibre-Channel resiliency gap
Fibre-Channel is still the predominant transport protocol for storage related data transmission. And rightfully so. Over the past +-two decades it has proven to be very efficient and extremely reliable in moving channel based data transmissions between initiators and targets. The reliability is due to the fact the underlying infrastructure is almost bulletproof. Fibre-Channel requires very high quality hardware as per FC-PI standard and a BER (Bit Error Rate) of less than 10^12 is not tolerated. What Fibre-Channel lacks though is an method of detection and notification to and from hosts if a path to a device is below the required tolerance levels which can cause frames to be dropped without a host to be able to adjust its behaviour on that path. Fibre-Channel relies on upper level protocols (like SCSI) to re-submit the command and that’s about it. When FC was introduced to the market back in the late 90’s, many vendors already had multipath software which could correlate multiple paths to the same LUN into one and in case one path failed it could switch over to the other. Numerous iterations further down the road nothing really exciting has been developed in that area. As per the nature of the chosen class-of-service (3) for the majority of todays FC implementations there is no error recovery done in an FC environment. As per my previous post you’ve seen that MPIO software is also NOT designed to act on and recover failed IO’s. Only in certain circumstances it will fail a path in a way that all new IO’s will be directed to one or more of the remaining paths to that LUN. The crux of the problem is that if any part of the infrastructure is less than what is required from a quality perspective and there is nothing on the host level that actively reacts on these kind of errors you will end up with a very poor performing storage infrastructure. Not only on the host that is active on that path but a fair chance exists other hosts will have the same or similar problems. (see the series of Rotten Apples in previous posts.)
So what is my proposal. Hosts should become more aware of the end-to-end error ratio of paths from their initiators to the targets and back. This results in a view where hosts (or applications) can make a judgement call of which path it can send an IO so the chances of an error are most slim. So how does this need to work. I is all about creating an inventory of least-error-paths. For this to be accomplished we need a way of getting this info to the respective hosts. Basically there are two ways of doing this. 1. Either create a central database which receives updates from each individual switch in the fabric and the host needs to query that database and correlate that with the FSPF (Fabric Shortest Path First) info in order to be able to sort things out or, and this would be my preferred way, we introduce a new ELS frame which can hold all counters currently specified in the LESB (Link Error Status Block) plus some more for future use or vendor specific info. I call this the Error Reporting with Integrated Notification frame. This frame is sent by the initiator to the target over all paths it has at its disposal. Each ingress port (RX port on each switch) which this frame traverses and increment the counters with its own values. When the target receives the frames it flips the SID and DID and send it back to the host. Given the fact this frame is still part of the same FC exchange it will also traverse the same path back so an accurate total error count of that path can be created.
Both options would enable each host of analyzing the overall error count on each path from HBA to target for each lun it has. The problem with option 1 is that the size of the database will increase exponentially proportional with the number of ports and paths and this might become such a huge size that it cannot live inside the fabric anymore and thus needs to be updated in an external management tool. This then has the disadvantage that host are depending on OOB network restrictions and security implications in addition to interop problematic issues. It also has the problem that path errors can be bursty depending on load and/or fabric behaviour. This management application will need to poll these switches for each individual port which will cause an additional load on the processors on each switch even while not necessary. Furthermore it is highly unreliable when the fabric is seeing a fair amount of changes which by default causes re-routing to occur and thus renders a calculation done by the host one minute ago, totally useless.
Option two has the advantage that there is one uniform methodology which is distributed on each initiator, target and path. It therefore has no impact on any switch and/or external management application and is also not relying on network (TCP/IP) related security restrictions, Ethernet boundaries caused by VLANS etc or any other external factors that could influence the operation.
The challenge is however that today there is no ASIC that supports this logic and even if I could get the proposal accepted by T11 it’ll take a while before this is enabled in hardware. In the meantime the ELS frame could be sent to the processor of the switch which in turn does the error count modification in the frame payload, CRC recalculation and other things required. Once more the bottleneck of this method will become the capability of the CPU of that particular switch especially when you have many high port-count blades installed . Until the ASICs are able to do this on the fly in hardware there will be less granularity from a timing perspective since each ELS frame will need to be sent to the CPU. To prevent the CPU from being flogged by all these update and pull requests in the transitional period there is an option to either extend the PLOGI to check if all ports in the path are able to support this frame in hardware or use this new ELS with a special “inventory bit” to determine the capabilities. If any port in the part does not not support the ELS frame it will flick it to 0. This allows the timing interval of each ELS frame to be inline with the capabilities of the end-to-end path. You can imagine that if all ports are able to do this in hardware you can achieve a much finer granularity on timing and hosts can respond much quicker on errors. If any port does not support the new ELS frame the timing can be adjusted to fall in between the E_D_TOV and R_A_TOV values (in general 2 and 10 seconds). The CPU’s on the switches are fairly capable to handle this. This is still much better than any external method of collecting fibre-channel port errors and having an out-of-band query and policy method. Another benefit is that there is a standard method of collecting and distributing the end-to-end path errors so even in multi-vendor environments it is not tied to a single management platform.
So lets look at an example.
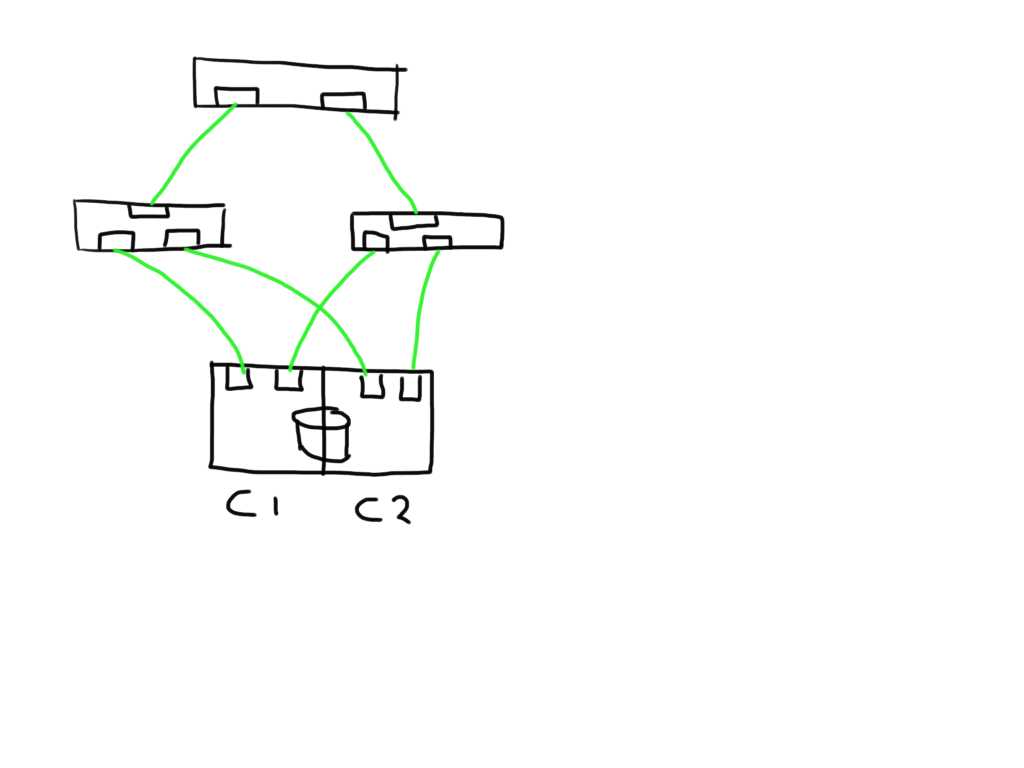 This shows a very simplistic SAN infrastructure where one host has 4 paths over two initiators to 2 storage ports each. All ports seem to be in tip-top shape.
This shows a very simplistic SAN infrastructure where one host has 4 paths over two initiators to 2 storage ports each. All ports seem to be in tip-top shape.
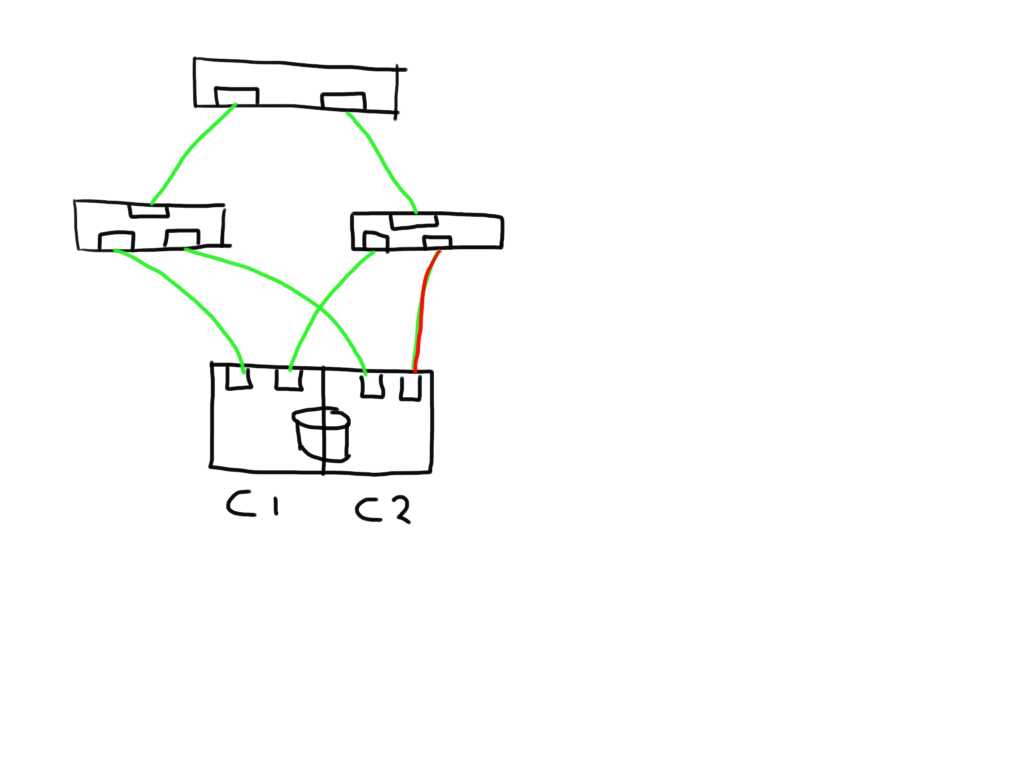 If one link (in this case between the switch and the storage controller) is observing errors (in any direction) the new ELS frame would increment that particular LESB counter value and the result would enable the host to detect the increase in any of the counters on that particular path. Depending on the policies of the operating system or application it could direct the MPIO software to mark that path failed and to remove it from the IO path list.
If one link (in this case between the switch and the storage controller) is observing errors (in any direction) the new ELS frame would increment that particular LESB counter value and the result would enable the host to detect the increase in any of the counters on that particular path. Depending on the policies of the operating system or application it could direct the MPIO software to mark that path failed and to remove it from the IO path list.
Similarly if a link shows errors between an initiator and switch it will mark 2 paths as bad and has the option to mark these both as failed.
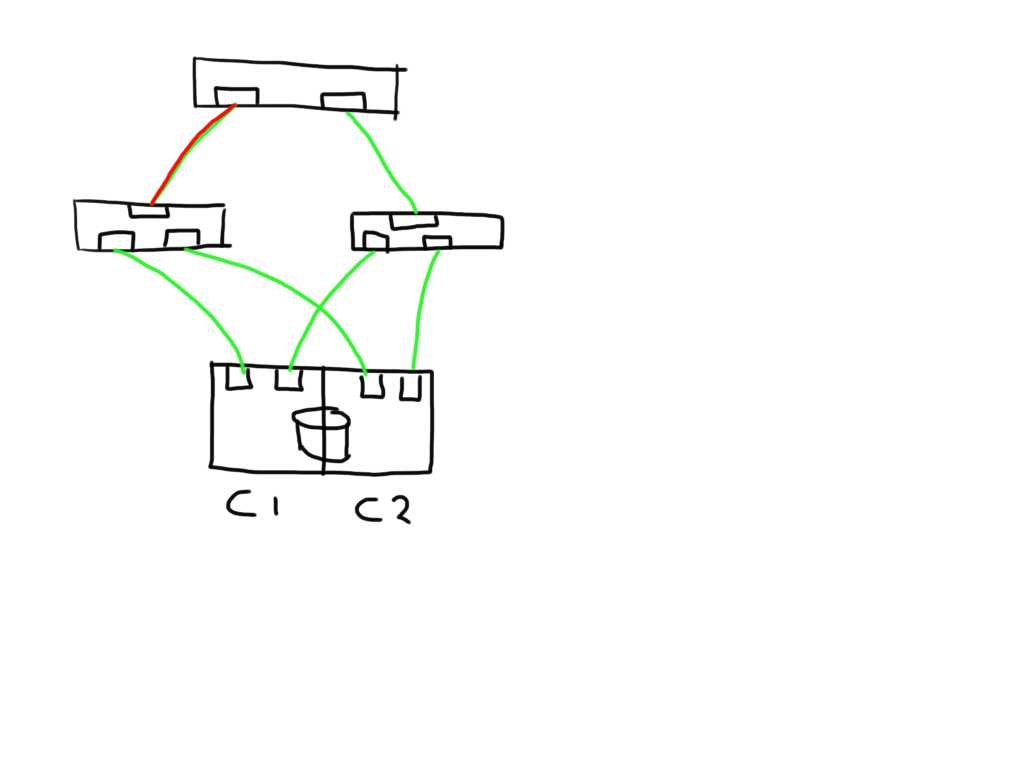 If you have a meshed fabric the number of paths exponentially grow with each switch and ISL you add. The below show the same structure but because an ISL has been added between the switches the number of potential paths between the host and LUN now grows to 8
If you have a meshed fabric the number of paths exponentially grow with each switch and ISL you add. The below show the same structure but because an ISL has been added between the switches the number of potential paths between the host and LUN now grows to 8
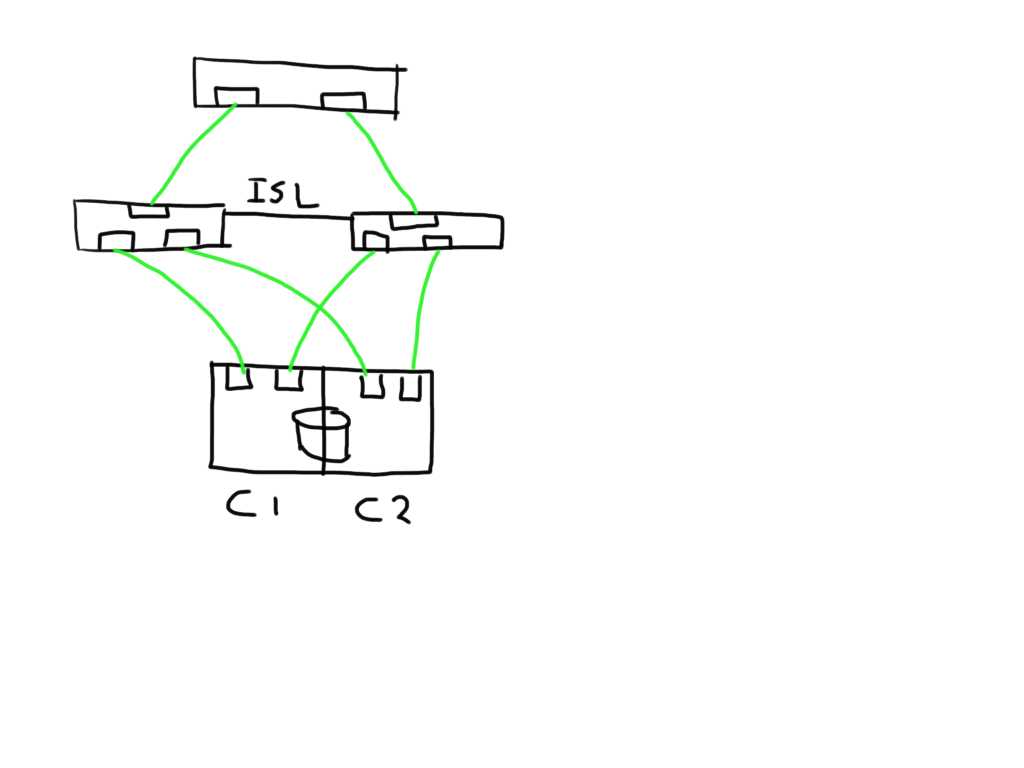 This means that if one of the links is bad the number of potential bad paths also duplicates.
This means that if one of the links is bad the number of potential bad paths also duplicates.
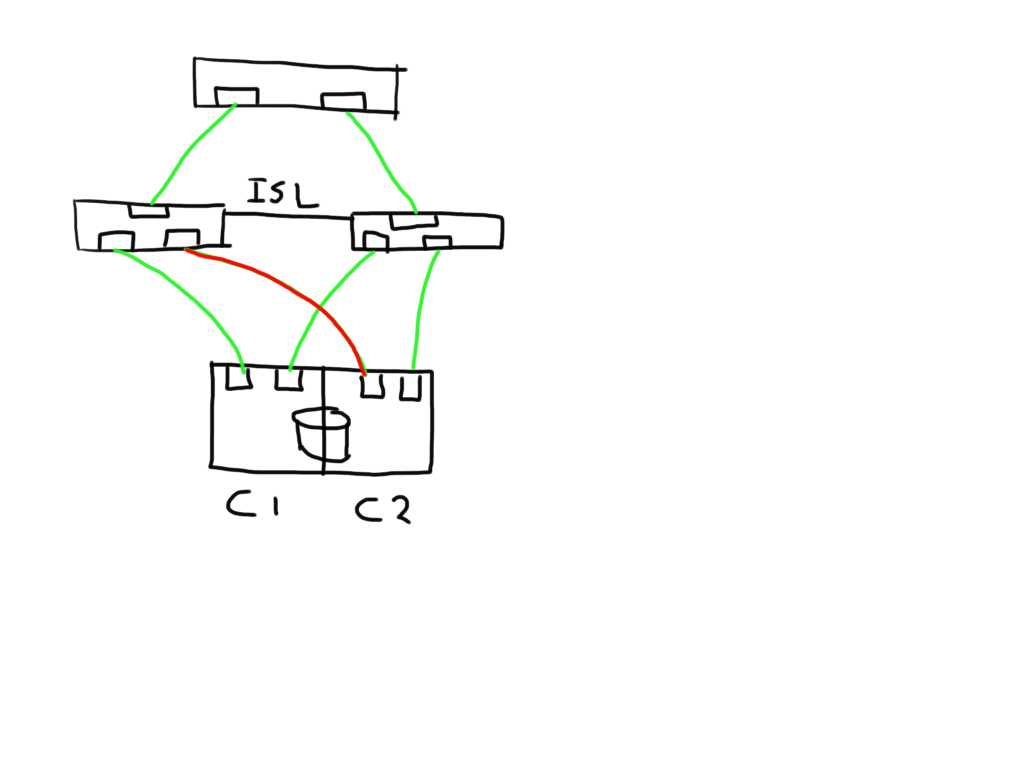 In this case the paths from both initiators on this bad link are marked faulty and can be removed from the target list by the MPIOsoftware.
In this case the paths from both initiators on this bad link are marked faulty and can be removed from the target list by the MPIOsoftware.
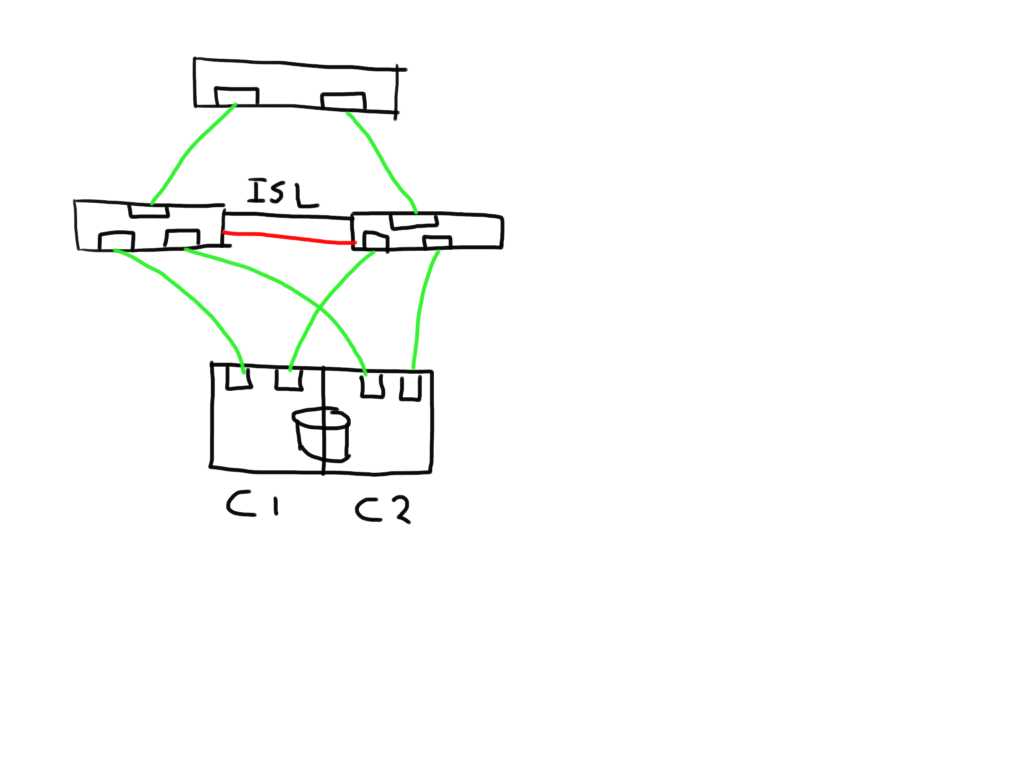 The fun really starts with the unexpected. Lets say you add an additional ISL and for some reason this one is bad. The additional ISL does not add new paths to the path-list on the host since this is transparent and is hidden by the fabric. Frames will just traverse one or the other irrespective of which patch is chosen by the host software. Obviously, since the ELS is just a normal frame, the error counters in the ELS might be skewed based on which of the two ISL’s it has been sent. Depending on the architecture of the switch you’ll have two options, either the ASIC accumulates all counters for both ports into one and add these onto the already existing counters, or you can use a divisional factor where the ASIC sums up all counters of the ISL’s and divides them by the number of ISL’s. The same can be done for trunks(brocade) / portchannels(Cisco). Given the fact that currently most the counters are used in 32bit transmission words the first option is likely to cause the counters to wrap very quickly. The second advantage of a divisional factor is that there will be a consistent averaging across all paths in case you have a larger meshed fabric and thus it will provide a more accurate feedback to the host.
The fun really starts with the unexpected. Lets say you add an additional ISL and for some reason this one is bad. The additional ISL does not add new paths to the path-list on the host since this is transparent and is hidden by the fabric. Frames will just traverse one or the other irrespective of which patch is chosen by the host software. Obviously, since the ELS is just a normal frame, the error counters in the ELS might be skewed based on which of the two ISL’s it has been sent. Depending on the architecture of the switch you’ll have two options, either the ASIC accumulates all counters for both ports into one and add these onto the already existing counters, or you can use a divisional factor where the ASIC sums up all counters of the ISL’s and divides them by the number of ISL’s. The same can be done for trunks(brocade) / portchannels(Cisco). Given the fact that currently most the counters are used in 32bit transmission words the first option is likely to cause the counters to wrap very quickly. The second advantage of a divisional factor is that there will be a consistent averaging across all paths in case you have a larger meshed fabric and thus it will provide a more accurate feedback to the host.
I’m working out the details w.r.t. the internals of the ELS frame itself and which bits to use in which position.
This all should make Fibre-Channel in combination with intelligent host-based software an even more robust protocol for storage based data-transmissions.
Let me know what you think. Any comments, suggestions and remarks are highly appreciated.
Cheers
Erwin
Does SNIA matter?
If your not into enterprise storage and live in France you might confuse the acronym with the Brotherhood of Infirmary Anaesthetics (Syndicat National des Infirmiers-Anesthésistes) but if you relate it to storage you obviously end up at the Storage Networking Industry Association.
This organisation is founded based upon the core values of developing vendor neutral storage technologies and open standards that enhance the overall usability of storage in general.
In addition the SNIA organises events such as Storage Networking World, Storage Developers Conference, summits and it also provides a lot of vendor neutral education with it’s own certification path.There are world-wide chapters who each organise their local gigs and can provide help and support on general storage related issues.
The question is though, to what extend is SNIA able to steer the storage industry to a point on the horizon that is both beneficial to customers as to the vendors. The biggest issue is that the entire SNIA organisation lives by the grace of it’s members, which are primarily vendors. Although you, as a customer or system integrator or anyone else interested, can become a member and make proposals, you have to bring a fairly large bag of coins to become a voting member and have the ability to somewhat influence the pathways of the storage evolution.
The SNIA does not directly steer development of technologies which are under the umbrella of the INCITS, IEEE, IETF and ISO standards bodies. Although many vendors are part of both organisations you will find that the well established standards such as FibreChannel, SCSI, Ethernet, TCPIP are developed in these respective bodies.
So should you care about SNIA?
YES !!!!. You certainly need to. The SNIA is a not-for-profit organisation which provides a very good overview of where storage technology is at every stage. It started of in 1997 shortly after storage went from DAS to SAN. Over the years it has provided the industry with numerous exciting technologies which enhanced storage networking in general. Some examples are SMI-S, CDMI, CSI, XAM etc. Some of these technologies evolved into products used by vendors and others have either ceased to exist due to lack of vendor support or customer demand.
If you’re fairly new in the storage business the SNIA is an excellent start to get acquainted with storage concepts, protocols and general storage technologies without any bias to vendors. This allows to remain clear minded of options and provides the ability to start of your career in this exciting, fast pace business. I would advise to have a look at the course and certification track and recommend to get certified. It gives you a good start with some credibility and at least you know what the pundits in the industry talk about when they mention distributed filesystems, FC, block vs file etc etc.
I briefly mentioned the events they organise. If you want to know who’s who in the storage zoo a great place to visit is SNW (Storage Networking World), an event organised twice a year in the US on both the east and west coast. All major vendors are around (at least they should in my view) and it gives you a great opportunity to check out what they have on their product list.
The next great event is SDC (Storage Developers Conference) which quite easily outsmarts most other geek events. This event is where everyone comes together who knows storage to the binary level. This is the event where individual file-system blocks are unravelled, HBA API’s are discussed and all the new and exciting cloud technologies are debunked. So if you’re into some real technical deep-dives this is the event to visit.
Although questions have been raised whether SNIA is relevant at all I think it is and it should be supported by anyone with an interest in storage technologies.
I’m curious about your thoughts.
Regards,
E
Fill Words. What are those, what do they do and why are they needed
There has been quite some confusion around the use of fill words with the adoption of the 8G fibre-channel standard. Some admins have reported that they have problems connecting devices on this speed as well as numerous headaches in long-distance replication especially when DWDM/CWDM equipment is involved.
An ordered set is a transmission word used to perform control and signaling functions. There are 3 types of ordered sets defined:
1. Frame delimiters. These identify the start and end of frames.
2. Primitive signals. These are normally used to indicate events or actions (like IDLE)
3. Primitive Sequences which are used to indicate state or condition changes and are normally transmitted continuously until something causes the current state to chance. Examples are NOS,OLS,LR,LRR
So what is a fill-word? A fill-word is a primitive signal which is needed to maintain bit and word synchronization between two adjacent ports. Is doesn’t matter what port type (F-port,E-port,N-Port etc) it is. They are not data frames in the sense that they transport user-data but instead they communicate status messages between these two ports. If no user-data is transmitted the ports will send so called IDLE frames. These are just frames with some bit pattern where the ports are able to keep there synchronization on a bit-level as well as a word level. The IDLE primitive is a 10-bit transmission character on the wire, as any ordered set starts with K28.5 which is a fibre-channel notation for 8B10B encoding and three data words of which the last 20 bits are 1010101010….etc. Depending on the content of these transmission characters it’s either a fill-word or non-fillword.
Examples of fillwords are IDLE, ARB(F0), ARB(FF) and non-fillword are R_RDY, VC_RDY etc.
So what happened recently with the introduction of the 8G standard.
In the 1,2 and 4G standard the IDLE primitive signal was used to keep bit and word synchronization. This bitpattern was OK on those speeds however it has been observed that when increasing the clock speed this pattern caused high emissions which in turn could cause problems on adjacent ports and links. In order to reduce that the standard now requires links that are using 8G speed to use the ARB(ff) fill-word. This is a different bit-pattern which doesn’t have this high emission characteristic.
You might wonder what does this have to do with my connection problem? If links negotiate on 8G speed they both have to use the ARB(FF) fill-word. If that doesn’t happen for some reason then the ports cannot maintain word synchronisation and therefore cannot change the port into the active state. This causes both ports to be in some sort of deadlock situation and although you may see that there is a green status light on your HBA and switch port it still is not able to transfer data.
The standard defines that ports who connect on 8G speed first have to initialize with IDLE fill-words and as soon as the port changes to the active state it should change the fill-word to ARB(FF).
It becomes even more complicated with DWDM and CWDM equipment particularly when multiplexers are used. These TDM devices normally crack open the fibre-channel link on a frame boundary level and then are able to multiplex this on a higher clock-rate so they are able to send data from multiple links into one wavelength. If however these TDM devices cannot open the fibre-channel link because they only look for IDLE fillwords then the end-to-end link will fail.
Verify with you manufacturer if you use TDM devices and if so do they support ARB(FF) fillwords. If not than you may have to force the linkspeed to a lower level like 4G.
The importance of clean fibre optics
I attended Cisco Live this week in Melbourne. Since it was very close to home and Cisco was kind enough to provide me with an entry ticket. (Many thanks for this.)
While strolling around the expo floor I ran into the nice people from Fluke Networks who were showing their testing equipment and of course I was very interested in the optical side of the fence. (I haven’t seen wireless storage networks yet so I’ll save that part of their impressive toolkit for later. :-)).
Since I’m doing troubleshooting as a day to day job I see many issues which have characteristics of a physical nature. This can be a bad cable, patch panel, SFP or anything in that nature.
Just when I wanted to start this blog post I saw that my Melbournian buddy Anthony Vandewerdt just beat me to it and wrote the article “Semmelweiss could see the problem” in which he described the problem of unclean cables and where it might lead to. (read this first and then come back here.)
In order to complement that article I’ll try to explain why this is so important.
I’m pretty sure that everyone these days know that computers work with bits which are either a 1 or 0. To be able to communicate with other computers (or devices in general) we use transmission of bits with either an on or off signal whether this being an electrical current or an optical wave. Electrical use has the nasty habit that the energy is partially stored in the capacitance of the electrical cable so it has a certain drop zone before it becomes a capacitor with 0 value. You can see this very well if you use a laptop charger with a small led. When you unplug it from the wall-socket it takes a couple of seconds before the current is completely gone from the capacitors in the transformer. This is also one of the primary reasons FC uses a 8b/10b encoding decoding schema to keep a balanced DC value.
The optical to electrical transformers have the same issue albeit not being in the cable itself but more in the physics characteristics of the circuitry. There is a certain fall-off and ramp-up time before current becomes completely zero and completely one respectively. This is very important since this depicts when a receiver should determine if the incoming bit should be seen as a 1 or are 0.
The optics people and companies represented in IEEE and T11-2 do write up the official metrics so this is all being done for you. There is nothing on a switch, array or other network equipment where you can tune this.
The measurement and characteristics of a signal can be measured with an oscillator. The result you see looks like this:

The blue lines show the voltage on the oscillator and this shows the, so called, eye-pattern. The hexagon in the middle is determine by the folks of IEEE and T11-2 and can be loaded as a software feature for ease of use on most equipment. (Note: be aware that this differs per technology and optical characteristic like FC, Ethernet, DWDM etc. )
The above picture shows a perfect eye-pattern since it show that the ramp-up time (from the bottom blue line to the top) is way before the “decision point” on becoming a 1 and the fall-off time is way after the decision point of becoming a 0.
“So what does this have to do with my fibre-cable” you may ask.
When connectors are not clean the light may be reflected back in to the cable causing jitter. It is this jitter that can significantly close the eye-pattern to a point where the receiver can no longer determine if an incoming light should be determined as a 1 or 0. The below picture show that this comes pretty close.

By default it will keep the same value it had on the previous clock cycle. This means that a one remains a 1 even though it actually should have been a 0 and vice versa. The result will be that the bitstream from the receiver buffer into the serdes chip will be incorrect thereby causing a decoding error. For FC it means that the er_enc_out or er_enc_in value on the LESB (Link Error Status Block) is incremented by one (depending if the 10-bit transmission word was part of a FC frame or not). On a Brocade switch in the porterrshow output this is shown in the enc_in or enc_out column.
If this happens on a bit which was part of a, normally valid, FC frame the frame now contains an invalid byte. If we not would have a fall-back mechanism this would have led to an invalid byte being send to the operating system and application causing corruption and even system failures. Since we also do a CRC check on the entire frame the destination port will discard it entirely and the upper layer SCSI stack (or whatever protocol resides on the FC4 layer) retry the IO.
The problem is that with distance you get loss of power (remember that light is measured in db’s). Depending on the type of cable (OM1,2,3,4) this budget loss on the cable is fixed. Every connection or splice (two optical cables welded together) adds to the link loss and decreases the optical power received on the other side of the link. The problem with dirty connections is that it significantly decreases the optical power which can cause the problem that the value in db the receiver can detect falls outside the specification of that particular SFP. This can cause link losses and port flapping causing all sorts of other nasty issues.
The link loss budget can be calculated based on the launch power of the transmitter, the number of connectors and splices in the cable-plant plus the margin on the receiver side.If this all falls below the receiver sensitivity mark the receiver will drop the link and the ports will go offline.

On a Brocade switch you can see the transmitter and receiver value with the “sfpshow” command:

The specifications of the SFP determine what the transmit and receive power should be. If the actual values of the RX power fall outside the specification of the SFP you should start to look at you cable’s, connectors and start cleaning them. If this doesn’t help there might be another problem like a crack in the cable or the SFP has a broken laser. In this case either replace the cable and/or SFP.
Hope this may help to explain why you might see strange things in your fibre channel network if the connectors are not clean and your support organisation is really stressing to fix and maintain your cable plant. I did mention I work in support and I see many connectivity issues resulting in flapping ports, overall performance issues and even data-loss or corruption.
If you want to know the characteristics of optical cables or SFP’s I suggest you have a look at the JDSU, Finisar or Avago websites. Also check out the FOA Youtube channel who uploaded some nice video’s which explain in detail the ins and outs of fibre optics.
Regards,
Erwin
Help, my Thin Provisioning is not working
On many occasions I’ve seen posts from storage administrator who mapped some luns to hosts and on the first use the entire pool got whacked with all bells and whistles going off. (Yes, we can control bells and whistles.:-))
The administrator did nothing wrong however he should have communicated with the server admin what the luns were for and how they were going to be used. As I mentioned in my previous post around Thin Provisioning is that the array doesn’t really know what’s going on from a host perspective. It know, due to HMO (port group settings) which type of host is connected and adjusts some internal knobs to accommodate for the commands from that particular host or application.
What it does not know is how that application is using the array.
Remember that a storage array just knows about reads and writes (besides the special commands specific for management).
In normal occasions a lun is mapped and on the host this lun is then formatted to a specific filesystem. Some filesystems use only the first couple of sectors of a disk to outline mapping of the blocks so if the application want to write a chuck of data the filesystem creates the inode, registers the mapping in the filesystem table in the beginning of the disk and away we go.
When we look at the disk from this perspective when formatted it looks like this:
————————————————————————————
|************ | | | | |
————————————————————————————
Only the first sector is written and the rest is still empty.
The same would happen if this lun was mapped out of a thin provisioned pool. Only the first couple of sectors on the virtual disk would be written, and therefore only the page occupying these sectors, would be marked as used in the pool, and the rest would still be empty and thus the array would not allocate them to this particular lun.
So far all is well.
The problem begins when the same lun is formatted with a filesystem which does interleaved formatting. The concept here is that the filesystem mapping table is spread over the entire disk which might improve performance if you do this on a single physical disk.
————————————————————————————
|** | ** | ** | ** | ** | **
————————————————————————————
On writes the chances that you’re able to update the mapping table, create the inodes and write the data in one stroke is fairly good.
Now compare the interleaved method to the one I described before and you will be able to figure out why this is really rendering This Provisioning useless. Since the chance is near 100% that all pages from that pool will be “touched” at least once, the entire page will be marked as used in that pool even though the net written data is next to nothing.
No you might think: “OK, I choose a filesystem which is TP friendly and I’m sorted”.
Well, not quite. Server administrator very often like to have their own “storage management tool” in the likes of volume managers. This allows them to virtualise “physical” luns mapped out of an array to a single entity in their systems.
The problem with this is that it will behave the same as the TP unfriendly filesystem with that difference that it’s not the filesystems doing the interleaving of metadata but now it’s the volumemanagers doing the same thing.
In both cases a TP pool will fill up pretty quickly without having an application write a single bit.
All storage vendors have whitepapers and instructions available how to plan for all these occasions. If you don’t want to run into surprises I suggest you have a look at them.
Regards,
Erwin van Londen
Fibre Channel improvements.
So what is the problem with storage networking these days? some of you might argue that it’s the best thing since sliced bread and it’s the most stable way to shove data back and forth and maybe it is however this is not always the case. The problem is some gaps still exist which have never been addressed and one of them is resiliency. There is a lot that has been done to detect errors and to try to recover from them but nobody ever thought of how to prevent errors from occurring. (Until now that is). Read on.
So what is the evolution of a standard like Fibre Channel.It normally is born out of a need that isn’t addressed with current technologies. The primary reason FC was erected is that the parallel SCSI stack had a huge problem with distance. It did not scale beyond a couple of meters and was very sensitive to electrical noise which could disturb the reliable transmission that was needed for a data intensive channel protocol like SCSI. So somebody came up with the idea to serialise the data stream and FC was born. A lot of very smart people got together and cooked up the nifty things we now take for granted like massive address-space, zoning, huge increase in speed and lot of other goodies which could have never been achieved with a parallel interface.
The problem is that these goodies are all created in the dark dungeons of R&D labs. These guys don’t speak much (if at all) to end-user customers so the stuff coming out of these labs is very often extremely geeky.
If you follow a path from the creation of a new thing (whether technology or anything else) you see something like this:
- Market demand
- R&D
- Product
- Sales
- Customers
- Post sales support
The problem is that very often there is no link between #5/#6 and #2. Very often for good reason but this also inflicts some serious challenges. Since I’m not smart enough to work in #2 I’m on the bottom of the food chain working in #6. 🙂 But I do see the issues that arise in this path so I cooked something up. Read on.
Going back to fibre channel there is one huge gap and that is fault tolerance and the acting upon failures in a FC fabric. The protocol defines how to detect errors and how to try to recover from these but is does not have anything which defines how to prevent errors from reoccurring. This means that if an error has been detected and frames get lost we just say “OK, lets try it again and see if it succeeds now”. It doesn’t take a genius to see that if something is broke this will fail again.
So on the practical side there are a couple of things that most often go wrong and that is the physical side of things like SFP’s and cables. These result in errors like encoding/decoding failures, CRC errors, signal and synchronization errors. If these occur the entire frame including your data payload will get dropped and we’re asking to the initiator of that frame to try and resend it. If however the initiator does not have this frame in it’s buffers anymore we rely on the upper layer protocol to recover from this. Most of the time it succeeds, however, as previously mentioned, if things are really broke this will fail again. From an operating system perspective you will see this as SCSI check conditions and/or read/write failures. On a tape environment this will often result in failed back/restore jobs.
Now, you’re gonna say “Hold on buddy, that why we have dual redundant fabrics, multiple entries to our LUNS, multipathing etc etc” i.e. redundancy. True, BUT, what if it is just partially broken? An dodgy SFP or HBA might send out good signals but there could also be a certain amount of not so good signals. This will result in intermittent failures resulting in the above mentioned errors and if these happen often enough you might get these problems. So, although you have every piece of the storage puzzle redundant, you might still run into problems which, if severe enough, might affect your entire storage infrastructure. (and it does happen, believe me)
The underlying problem is that there is no communication between N-Ports and F-ports as well as lack of end-to-end path error verification to check if these errors occur in the fabric and if so how to mitigate or circumvent these. If an N-port sends out a signal to an F-port which gets corrupted underway there is no way the F-port is notifying the N-port and saying “He, dude you’re sending out crap, do something about it”. Similar issue is in meshed fabrics. We all grew up since 1998 with FSPF (Fabric Shortest Path First) which is a FC protocol extension to determine the shortest path from A to B in a FC fabric based on a least cost routing algorithm. Nothing wrong with that however what if this path is very error prone? Does the fabric have any means to make a decision and say “OK, I don’t trust this path, I’ll direct that traffic via another route”? No, there is nothing in the FC protocol which provides this option. The only way routes are redefined is if there are changes in the fabric like an N-Port coming online/offline and registers/de-registers itself with the fabric nameserver and RSCN (Registered Name Change Notifications) are sent out.
For this reason I submitted a proposal to the T11 committee via my, teacher and father of Fibre Channel Horst Truestedt, to extend the FC-GS services with new ways to solve these problems. (proposal can be downloaded here )
The underlying thoughts are to have port-to-port communication to be able to notify the other side of the link it is not stable as well as have and end-to-end error verification and notification algorithm so that hosts, hba’s and fabrics can act upon errors seen in the path to their end devices. This allows active redirection of frames to circumvent frames of passing via that route as well as the option to extend management capabilities so that storage administrators can act upon these failures and replace/update hardware and/or software before the problem becomes imminent and affects the overall stability of the storage infrastructure. This will in the end result in far greater storage availability and application uptime as well as prevent all the other nasty stuff like data corruption etc.
The proposal was positively received with an 8:0 voting ratio so now I’m waiting for a company to pull this further and actually starting to develop this extension.
Let me know what you think.
Regards
Erwin