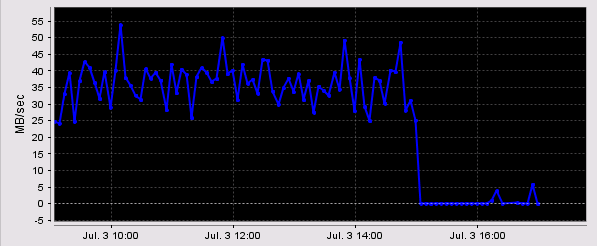
As some of you may recall about a decade ago I made a proposal to incorporate more intelligence into the end-devices to be able to better react to changing conditions in fabrics. I called it the “Error Reporting with Integrated Notification” framework (mind the acronym here. :-))
Basically the intention was to have end-devices check for errors along paths which their frames traverse by sending a “query-frame” to the remote device. Each hop along the way could then add its values (errors, counters) to that frame and the remote device would, upon reception of that frame, also add its counters, reverse the SID (Source ID) and DID (Destination ID) and send that same frame back to the original sender. That sender would then be able to make decisions whether to use that same path for subsequent frames or if it would hold of using it temporarily or not at all. Read on.