When you work from home and are required to use the corporate network you’re often shoved into a dilemma where the VPN configuration that is pushed to your PC results in one of two modes, Full-tunnel or Split-Tunnel.
Digging tunnels
A full-tunnel configuration is by far the most dreadful especially when your VPN access-point is on the other side of the planet. Basically all traffic to and from your system is pushed through that tunnel. This is even the case when a web-page is hosted next-door from where you are sitting. Your requests to that webserver will first traverse via your VPN connection to the other side of the planet where your companies proxies will retrieve the page via the public web only to send it back to you via that VPN again. Obviously the round-trip and other delays will basically result in abominable performance and a user-experience that is excruciatingly painful.
A split-tunnel however is far more friendly. As I explained in one of my previous articles (here) only traffic destined for systems inside your corporate network will be routed over the VPN and requests to other systems will just traverse the public interweb.
Domain Name resolution
There is however one exception DNS i.e. the name to (IP) number translation. Traditionally Linux uses a system-wide resolver that looks in “/etc/resolve.conf” what you DNS servers are and which domains to search for plus a few other options. That basically means that as soon as you have any VPN tunnel active you would always need to use your corporate DNS servers for any request as your system does not really know which server is located where. There may even be a situation that your corporate DNS servers point to a different host for the same domain. You often see this where employees get additional functionality than external users or credential verification may be bypassed as you already have an authorised session to the internal systems.
The drawback is however that sites outside your corporate network are also resolved via your companies DNS servers. This may not only be a limitation on performance from a resolver standpoint, remember that these DNS requests also have to traverse the same VPN tunnel, but the resulting system to where you end up may also not be the most appropriate one.
As an example.
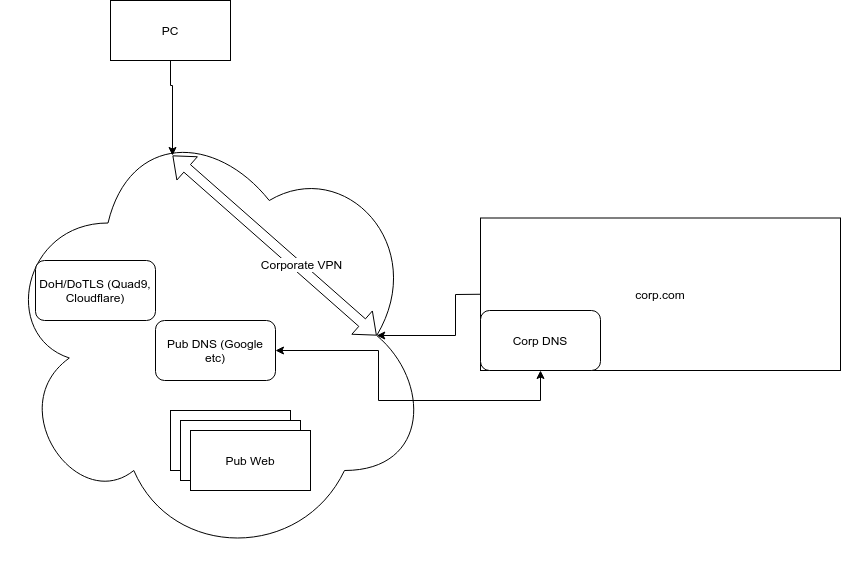
If you have an active VPN to your corp.com, even DNS queries for a web-site in your country will first go “Corp DNS” who, if it does not already have a cached address itself, will forward that request to whatever “Corp DNS” has configured as its upstream DNS server. (In this case Google). As you can see you could’ve asked Googles DNS servers yourselves but as you VPN session has set your resolver to use the Corp DNS that does not happen. An additional point of attention is that you have to be aware of is that no matter which website you visit your company will have a record of that as most corporate regulations stipulate that actions done on their systems will be logged for whatever purpose they deem necessary. This may sometime conflict with different privacy policies in different countries but that is most often shuffled under the carpet and hidden in legal obscurity.
The above also means that when you have requests for sites that span geographies, you may not always get to the most optimal system. Many DNS system are able to determine where the request is coming from and subsequently provide a IP address of a system that is closest to the requestor. As your request is fulfilled by your companies’ DNS server on the other side of the planet, that web-server may also be there. Not to panic as many of these environments have build in smarts to re-direct you to a more local system it nevertheless means this situation is far from optimal. What you’re basically after is to have the ability to, in addition to that split-tunnel configuration, direct DNS queries to DNS servers which actually host the domains behind that VPN and nothing else.
In the above case your Linux system has two interfaces. One physical (WIFI or Ethernet) and one virtual (VPN most often called tunX where X is the VPN interface number)
Meet systemd-resolved
There are some Linux (or Unix) purists who shudder at the sight of systemd based services but I think most of them are actually pretty OK. Resolved is one of them.
What resolved allows you to do is assign specific DNS configurations to different interfaces in addition to generic global options.
As an example
Global
LLMNR setting: yes
MulticastDNS setting: yes
DNSOverTLS setting: no
DNSSEC setting: allow-downgrade
DNSSEC supported: no
Fallback DNS Servers: 9.9.9.9
DNSSEC NTA: 10.in-addr.arpa
16.172.in-addr.arpa
168.192.in-addr.arpa
<snip>
31.172.in-addr.arpa
corp
d.f.ip6.arpa
home
internal
intranet
lan
local
private
test
Link 22 (tun0)
Current Scopes: DNS LLMNR/IPv4 LLMNR/IPv6
DefaultRoute setting: yes
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: no
DNSSEC setting: no
DNSSEC supported: no
Current DNS Server: 10.15.230.6
DNS Servers: 10.15.230.6
10.15.230.7
DNS Domain: corp.com
internal.corpnew.com
Link 3 (wlp0s20f0u13)
Current Scopes: DNS LLMNR/IPv4 LLMNR/IPv6
DefaultRoute setting: yes
LLMNR setting: yes
MulticastDNS setting: no
DNSOverTLS setting: no
DNSSEC setting: yes
DNSSEC supported: yes
Current DNS Server: 192.168.1.1
DNS Servers: 192.168.1.1
DNS Domain: ~.
ourfamily.int
As you can see it has three sections. The global section caters for many default settings which can be superseded by per-interface settings. I think overview speaks for itself. All requests to domain “corp.com” and “internal.corpnew.com” will be sent to one of the two DNS servers with the 10.15.230.[6-7] adress. All my home internal requests as defined by the “ourfamily.int” domain are sent to the 192.168.1.1 address. The “~.” means all other requests.
That will result in queries being returned like:
[1729][erwin@monster:~]$ resolvectl query zzz.com
zzz.com: 10.xx.16.9 -- link: tun0
10.xx.16.8 -- link: tun0
172.xx.24.164 -- link: tun0
172.xx.24.162 -- link: tun0
10.xx.100.4 -- link: tun0
10.xx.148.66 -- link: tun0
10.xx.7.221 -- link: tun0
10.xx.7.34 -- link: tun0
10.xx.7.33 -- link: tun0
10.xx.100.5 -- link: tun0
-- Information acquired via protocol DNS in 243.1ms.
-- Data is authenticated: no
If I would use an external DNS system for that domain it would return different addresses.
[1733][erwin@monster:~]$ dig @9.9.9.9 +short zzz.com
169.xx.75.34
(The above are not my real domains I queried but I think you get the drift)
Queries to non-corporate websites will be retrieved via the WIFI interface (wlp0s20f0u13)
[1733][erwin@monster:~]$ resolvectl query google.com
google.com: 2404:6800:4006:809::200e -- link: wlp0s20f0u13
216.58.203.110 -- link: wlp0s20f0u13
-- Information acquired via protocol DNS in 121.0ms.
-- Data is authenticated: no
As my home router has a somewhat more sophisticated setup this also allows me to have all external DNS requests, not destined to corp.com or corpnew.com, use a DNSoverHTTPS or DNSoverTLS configuration to bypass any ISP mangling.
Setup
Systemd-resolved is a systemd service (duhh) which needs to be enabled first with “systemctl enable systemd-resolved“. The configuration files are located in /etc/systemd/resolved.conf or in a .d subdirectory of that where individual configuration files can be stored.
-rw-r--r-- 1 root root 784 Oct 20 14:32 resolved.conf
drwxr-xr-x 2 root root 4096 Oct 20 14:24 resolved.conf.d/
The settings can also be applied interactively via the “resolvectl” command which I have done. If your distro has NetworkManager installed then NM can also automatically configure resolved via D-bus calls.
There is more involved than I can easily simplify here as it would pretty quickly become a re-wording of the man-page which I try to avoid. At least I hope it has given you some information of what you can do with “systemd-resolved”
Kind regards,
Erwin




