
As some of you may recall about a decade ago I made a proposal to incorporate more intelligence into the end-devices to be able to better react to changing conditions in fabrics. I called it the “Error Reporting with Integrated Notification” framework (mind the acronym here. :-))
Basically the intention was to have end-devices check for errors along paths which their frames traverse by sending a “query-frame” to the remote device. Each hop along the way could then add its values (errors, counters) to that frame and the remote device would, upon reception of that frame, also add its counters, reverse the SID (Source ID) and DID (Destination ID) and send that same frame back to the original sender. That sender would then be able to make decisions whether to use that same path for subsequent frames or if it would hold of using it temporarily or not at all. Read on.
Fast forward to 2021 and the folks in T11 ran along with the idea but used a more fabric-centric and, I must admit, more manageable method.
FPIN – The Holy Grail of SAN Stability
FPIN stands for Fabric Performance Impact Notification and is a framework that is, or will be, incorporated in the various T11 FC standards like FC-LS, FC-FS and FC-SW.
The FPIN framework is based on a process of registration and notification of a diverse set of counters and thresholds that can signal or notify adjacent or remote N-ports of issues along its pathway. One thing to be aware of is that the terminology of signalling and notification has a different meaning here. Signalling is ALWAYS done via primitive signals (ie NOT frames but ordered sets) and notifications is done via frames from a source anywhere in the fabric to a destination anywhere in the fabric.
So how does it work
At the time of writing the FPIN framework is not yet set in concrete but its just a matter of dotting the “i”‘s and crossing the “T”‘s. Brocade, Emulex, Qlogic (ie Broadcom 2x and Marvel) and IBM AIX as well as RHEL 8.3 have support for the functionality. (!!! Be aware: update your FIRMWARE & DRIVERS to the latest versions !!!)
Basically what is boils down to is that a device (Nx-port) does it’s normal thingy when starting up. You get you usual FLOGI, PLOGI etc but when it supports FPIN it will also send a few new ELS commands.
EDC – Exchange Diagnostics Capabilities.
The first one is the EDC wich stands for “Exchange Diagnostics Capabilities”. This frame is directed to the F-port controller (ie the switch port which it connects to). That EDC contains the descriptors of the diagnostics capabilities it has. If the switch also supports these, an accept of these descriptors will be sent back to the N-port. At the time of writing, there are two; the Link Fault Capability descriptor and the Congestion Signalling descriptor.
The first one is build on top of the Reed-Solomon FEC logic containing 3 parameters
- FEC Degrade Interval
- Degrade Active Threshold
- Degrade De-Activate Threshold.
These three parameters are used to identify link-integrity issues and be able to issue primitive signals to adjust link workload and reduce frame corruption.
The second one, Congestion Signalling descriptor, is a means to notify the Nx- or F-port to reduce traffic-load, or in case of a signal clear allow more traffic. This way allows fabric services as well as end-devices to balance the workload more effectively and not rely on buffer-credit allocation to regulate frame-flow. Don’t be fooled, Buffer-to-Buffer credit mechanism is still active and will always take a priority. The Congestion Signalling methodology is helping in preventing credit starvation. Credit starvation anywhere in a fabric can and will result in back-pressure as well as is mostly the cause of dropped frames due to timeouts.
RDF – Register Diagnostic Functions
The RDF ELS command frame is the way for an Nx-port to notify the fabric which diagnostic functions and values it can provide. This frame is not sent to the F-port controller but to the Fabric-controller address. These functions are registered in the form of TLV (Tag, Length and Value)descriptors which allows multiple functions to be advertised in the fabric. At the time of this writing, the first one is the FPIN function. In due course, more functions can be developed in the respective standards utilising the same RDF method by simply adding more functions and adding the descriptors to the RDF ELS frame.
Be aware that the FPIN function is the first one that is registered via the RDF method. Other functions may use different ELS commands and responses using other TLV’s. An example of another ELS is the RDP (Read Diagnostic Parameters) which can send that ELS to a remote device with one of the TLV’s it would like to have information of such as SFP diagnostics, link-error-status-block info etc.
The problem.
The Fabric Performance Impact Notification is not really a direct request and response method, as in my earlier proposal, but more a methodology based on event or state change subscriptions. If something happens in the fabric or end-device, these entities can notify other devices that may be affected by that event or state of the affected device.
If, for example, a device internally detects that it has issues handling data at arrival rates currently being received from the fabric, it can inform the fabric with a primitive signal indicating it has reached or is near capacity of its handling capabilities. The F-port attached to that device knows which other devices are zoned to the congested one and is then able to notify the WWPN’s that have registered with the TLV’s via the RDF during initialisation and can therefore reduce the amount of frames it sends to that congested device.
As an example

Server 1 issues a read-request to the array. The array sends the data as quickly as possible to the initiator, with its only restriction being the number of buffer-credits it knows from the F-port to which it connects to. The switch will try to offload these frames as quickly as possible, but at some stage runs into a state where the HBA of Server 1 slows down and restricts the number of credits it has available by not sending enough R_RDY primitive signals back to the switch port. The switch will therefore at some stage also impose the same restriction onto the array port by withholding these credits. This means that the array is no longer able to send frames to any of the servers it is zoned to (Server 1 but also 2, 3, 4 and 5). This will obviously result into a situation where all sorts of recovery timers start kicking in and link-resets will cause these credits to be replenished at the cost of failed IO’s. These will then need to be re-driven by the hosts/application. Obviously, this incurs a huge performance and reliability impact.
Things get worse
The above example is only a simple representation of a single array over single switch setup. What if the construction becomes a bit more complex?
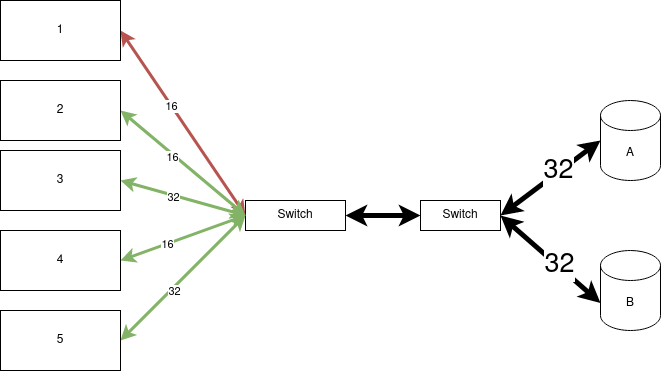
Now what happens is that the credit shortage will cause credit back-pressure onto the ISL between the two switches. A result of that is that traffic from array 2 to server 4 will also be impacted as the right-hand switch is not able to send traffic over the ISL at all. I know, I know, there are a few workarounds like SDDQ, using different QoS lanes etc but the overall problem remains.
Here comes FPIN
Now if server 1 was able to send a signal to the port of the switch to which it is connected to, indicating it has reached a warning threshold, that switch would then be able to associate the traffic flow from server 1 to array A and send array A a FPIN that server 1 is congested. Array A would then be able to reduce the workload to server 1 and therefore not only resolve the problem on Server 1 but also prevent the credit back-pressure on the ISL and thus preventing traffic-flow issues between other initiator and target pairs.
It also works the other way around. If server 1 is no longer observing congestion issues, ie its workload has dropped below the threshold, it will also inform that F-port and the notification will be sent to any interested party (ie any device that has registered support for that TLV.) and normal traffic can resume.
As the concept of FPIN is very dynamic, the FC standards only describe the methodology. It does not contain any values of thresholds and timings. All of this is device dependant and is always inexplicably linked to the performance capabilities of the end devices.
In a future post I will provide some more examples and dive into some configuration and diagnostics options.
A Youtube video showing capabilities of FPIN on a Brocade and AIX platform below.
Please accept YouTube cookies to play this video. By accepting you will be accessing content from YouTube, a service provided by an external third party.
If you accept this notice, your choice will be saved and the page will refresh.
Let me know if you want to know more about this.
Regards,
Erwin
