
System administrators are very inventive and lazy. I know, I used to be one of them. 🙂 Everything that can be done to make ones life easier is about to be scripted, configured, designed etc. If you are responsible for an overall environment from Apps to servers to networks and storage you can make very informed decisions on how you want to set up each different aspect of your environment. The last time I had this opportunity was back in 1995. Since then I have not come across an environment where a single person/team was responsible for each technology aspect of the infrastructure. As environments grow these teams grow as well. Business decisions like splits, acquisitions, outsourcing etc etc have enormous impacts not only on the business itself but also on people who are now forced to work with other people/teams who may have different mind-sets, processes and procedures and even completely different technologies. In many such instances strange things will happen and result in a very unpredictable behaviour of compute, network and storage systems. Below I’ll give you such an example where decisions from a systems-level perspective results in massive problems on a storage network.
Host based mirroring of disk is as old as the first operating systems in the late sixties and early 70-ties. Unix, VMS, MVS, NSK al had some sort of transparent synchronization of two or more disks for redundancy reasons. The introduction of RAID by Gibson, Patterson and Katz (see here) in the mid-80-ties resulted in the functionality to be somewhat forgotten as specialized hardware controllers would make sure of redundancy in case a disk failed. As disk-sizes grew the restore-time of a single disk failure grew with it and as both were almost aligned to Moore’s Law the associated risks grew with them in an exponential fashion. In such cases separate disk systems were connected to each other and some form of hardware based replication made sure that availability was warranted in case storage system A failed so storage system B could proceed. All sorts of smarts were introduced to keep downtime as low as possible.
As time progressed and reached the era of “near 0” downtime the host system architectures and CPU’s kept fairly well in pace with Moore’s Law. In the second decade of the new millennium these systems became so fast that a huge amount of features and functions that were previously handed off to special hardware, were now able to be handled by software again. With the introduction of host based virtualization on the x86 platforms other features such as networking was also brought back into the hosts. The same thing happened with storage. As CPU’s were no longer a real bottleneck and system busses as PCI-E were able to move back and forth huge amounts of data a similar phenomenon happened once more with disks.
New, software based, storage architectures were invented and came to life in products like VMware VSAN, Ceph, Gluster and Amazon S3.
Another phenomenon was the introduction of smart file-systems and volume managers. ZFS is one of them which leads me to the problem I described in the title.
Return of HBDM (Host Based Disk Mirroring)
As system administrators wanted more flexibility from their, maybe already existing, storage environment and did not want to be constrained by limitations (whichever they might think of) imposed by the storage systems, I did see a return of the disk mirroring software ramping up. Again raw volumes were pooled together on a volume-manager and/or filesystem layer and provisioned to the OS to be used by applications. This works quite well if all characteristics of all these underlying disks are merely the same. If one or more falls out of line you get very unpredictable results.
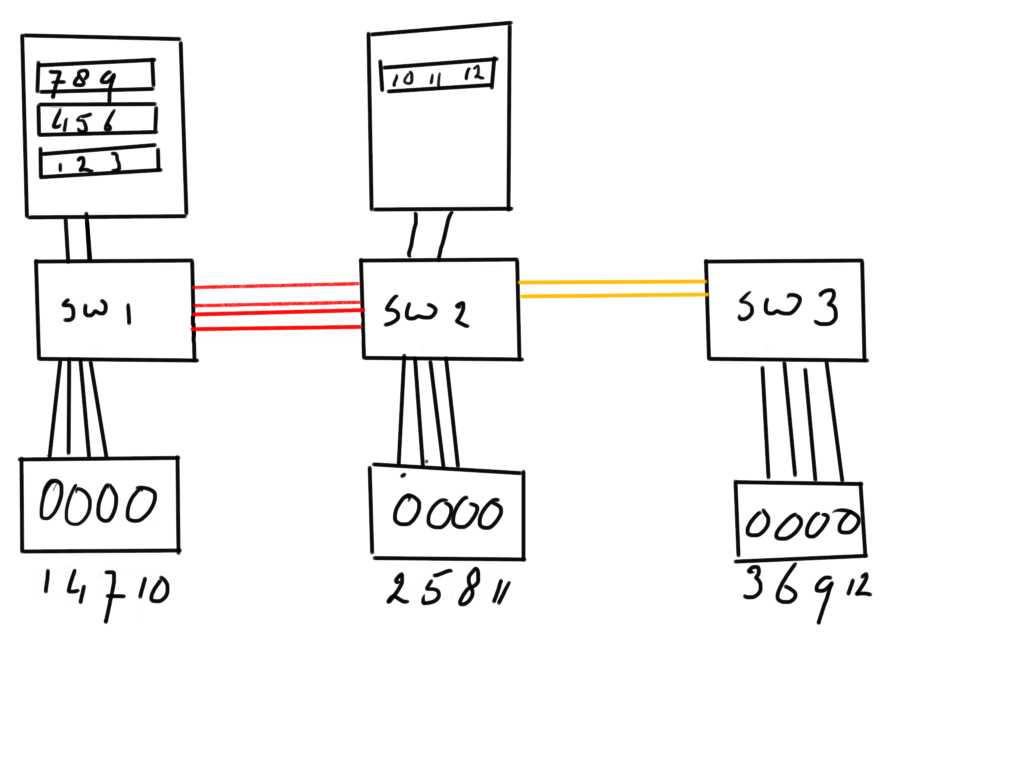
One of the things (characteristics) a host is unable to determine is location. When a disk is provisioned to a host there are no flags or entities in the SCSI VPD pages or Fibre-Channel characteristics which tell the host that a volume is provisioned from a location A or B (or even C). To the host that disk just observes some physical and logical characteristics such as number of blocks, vendor, UUID, BTL and a few more which may or may not add functionality such as clustering support, ATS, TRIM etc… Location is not one of those and most certainly not distance.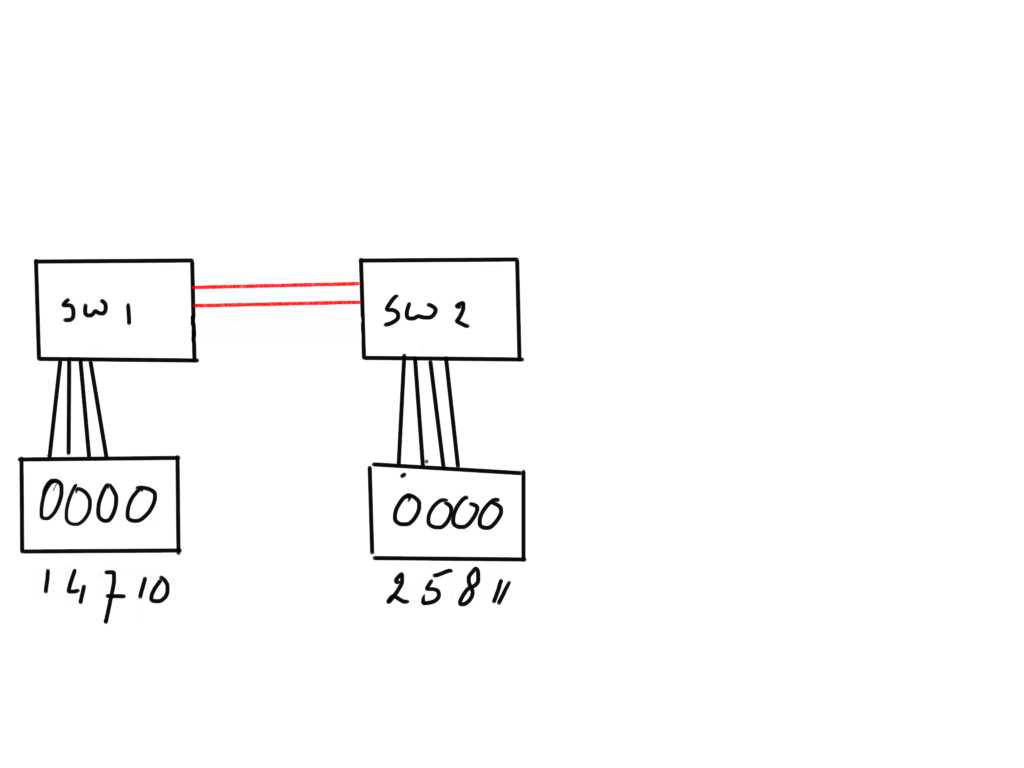 In the above example (pardon my lack of drawing skills) I have two FC switches connected via two ISL links. Each switch sits on a different location and the ISL may be over 20 kilometers long. That normally is no problem from a connectivity perspective.
In the above example (pardon my lack of drawing skills) I have two FC switches connected via two ISL links. Each switch sits on a different location and the ISL may be over 20 kilometers long. That normally is no problem from a connectivity perspective.
The switches have each a storage array connected from which volumes 1,2,4,5,7,8,10 and 11 are provisioned to a host:
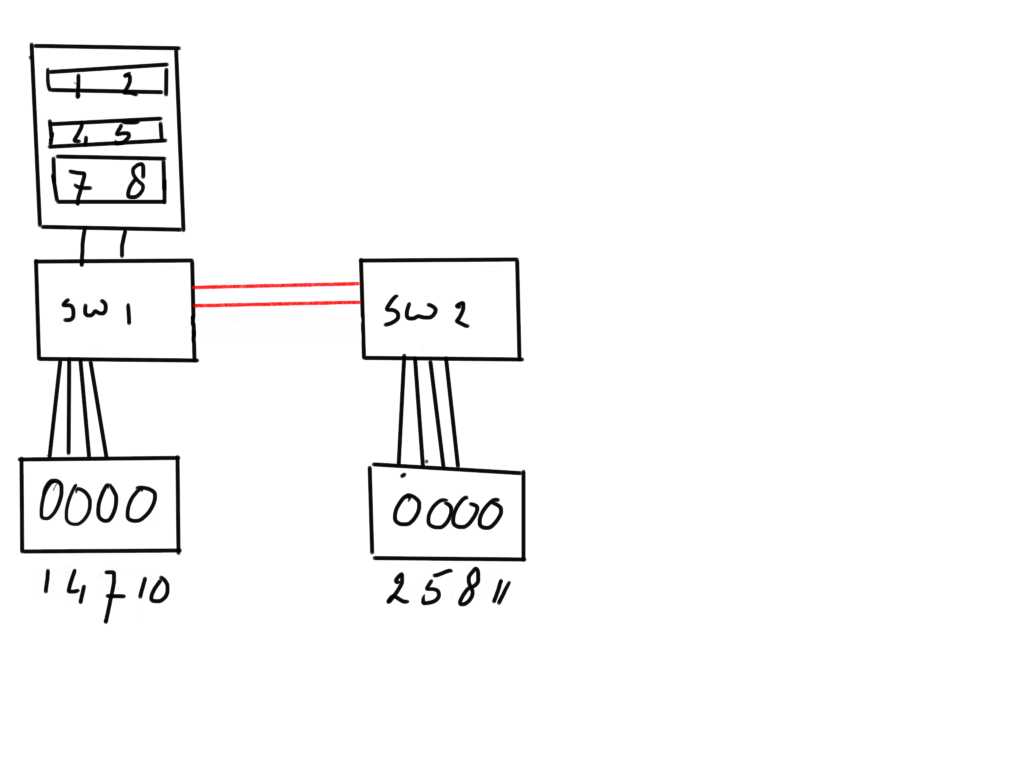 On the host these individual disks are grouped together in three mirror sets of weach each member is dispersed over the two location. From a redundancy standpoint this provides a very nice solution as when you have a standby system on the site where SW2 is located you just need to spin that one up and away you go.
On the host these individual disks are grouped together in three mirror sets of weach each member is dispersed over the two location. From a redundancy standpoint this provides a very nice solution as when you have a standby system on the site where SW2 is located you just need to spin that one up and away you go.
The problem with this is during day-to-day operations. As you can imagine each WRITE IO will need to go to both indiviual disk before the filesystem or volume manager can complete the transaction and inform the application the data is stored successfully. That means that with fairly heavy write workloads each individual IO will only be acknowledged when both individual write operations are completed and therefore there will be a high delay in application response time.
Furthermore since the host has no clue of location each READ IO will be sent in a round-robin fashion which leads to the problem that one IO may complete fairly quickly but the next takes a very long time as it needs to traverse that distance.
So not only will it impose an natural (unfixable) delay but it will also cause a huge amount of traffic over these ISL’s from SW2 back to SW1 and back up the host. Since this delay then results in increased queuing on the host, any subsequent IO request from the application may also suffer from an elongated response time.
The problem becomes even more exacerbated when additonal disks are provisioned from even a third location.
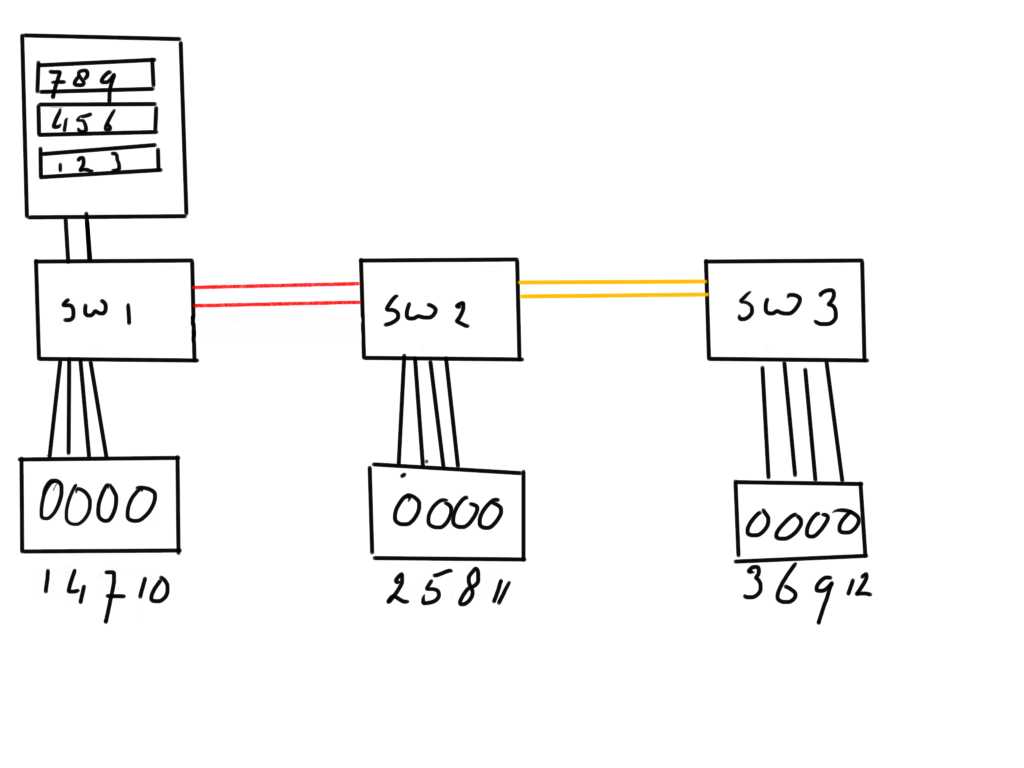 This will result in the fact that the ISL from SW1 to SW2 not only carries traffic from disks 2,5,8 and 11 but also from 3,6,9 and 12.
This will result in the fact that the ISL from SW1 to SW2 not only carries traffic from disks 2,5,8 and 11 but also from 3,6,9 and 12.
From a pure fibre-channel perspective the problem is even worse.
As these ISL are a shared everything link the switching algorithm is indiscriminate of which frames get sent first. (I don’t take into account QoS and VC dispersion here but that does influence this particular problem very much). So when Host A is sending a read request to disk 3 it has to traverse two hops. If an already ongoing transfer from disk2 back to the host is highly utilizing the ISL between SW2 and SW1 you may see a very high buffer credit depletion ratio on the e-gress port of the ISL’s back to SW1 but also possible timeouts on either the Egress ISL ports on SW3 or the ingress ports from the array connected to SW3.
The problem becomes even more painful when a similar host setup is configured on site 2 and it obtains its disks from all three sites as well. Neither the hosts nor the storage arrays have any notion of the amount of requests and workload each individual entity submits and therefore they can significantly impact each other.
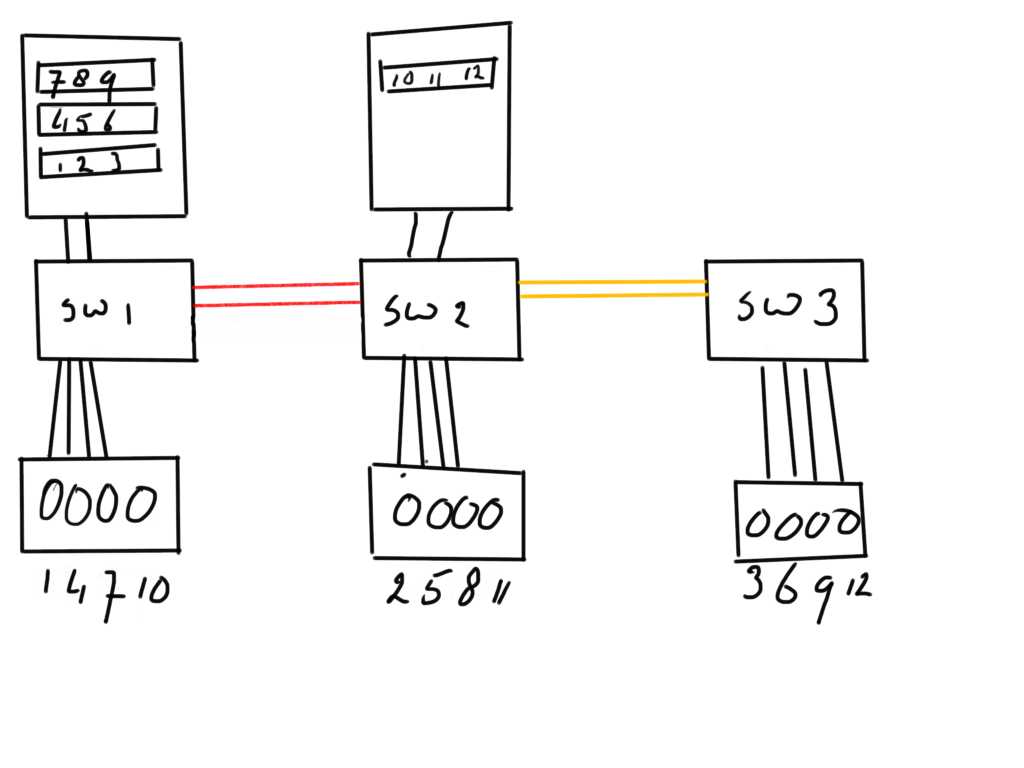 The only thing you see from a host perspective is an exponential delay in IO completion time obviously resulting in performance problems.
The only thing you see from a host perspective is an exponential delay in IO completion time obviously resulting in performance problems.
These problem are then most often pushed onto the storage teams but given the fact thisis an architectural design problem from an overall systems perspective there is not much one can do.
Sometimes I see storage administrators add ISL’s or start massively increasing buffer-credits on ISLs but that only alleviates a very tiny bit or, in many cases, has an even adverse effect as the queuing is then also pushed onto the fabric. This may lead to a significant buffer-credit problem when one or more hosts observe these IO delays and start pushing back credits wich then flow onto switches and ISL’s.
 As you can see the above example is just for one or two hosts and may be easily resolved by some tricks. These tricks go out the window if you reach 5 or hosts with the same or similar configuration.
As you can see the above example is just for one or two hosts and may be easily resolved by some tricks. These tricks go out the window if you reach 5 or hosts with the same or similar configuration.
I can understand the wish for such a setup as it is relatively easy to design and configure however from a storage perspective it results in being the ultimate nightmare as there is nothing storage administrators can do to resolve this. They depend totally on the host configuration and workload characteristics. Storage administrators cannot defy physics so photons will not travel faster when you have configured a ZFS pool over multiple locations.
Host options
A few options that can improve this situation.
- Make sure that all READ requests remain local. Unfortunately there are only limited software solutions that allow such a configuration. ZFS on Solaris is unable to do that. The OpenZFS on Linux has some patches moved into some forks with allows a preferred read volume but these are not provided in the upstream kernel.
- Veritas (or Symantec) Volume Manager provides the options to create a so called “preferred plex” which directs the IO to that volume unless other priorities are triggered. OpenVMS has the same function since almost day 1 where it allows you to set a site-id in the shadowset instructing the OS to send read requests to that volume member first. (This is even cluster aware so that in case of a cluster failover the previously remote disk is then considered local.)
- Software Storage solutions like Oracle ASM provides a similar function where you can create a logical extent as a preferred read failure group.
- In other, non location aware, configurations you may need to create snapshots to be send to a remote volume. The amount of snapshots, change-rate and RPO obviously determine what your design will look like. The benefit is that roll-backs are very easy and the impact on the storage network is very controllable as these snapshots can always be scheduled.
- Use a storage based replication solution. Many options have been developed in the past two decades to achieve a 0 or near-0 downtime configuration. Even storage based clustering solutions like GAD from HDS provides options to significantly increase control on SAN traffic whilst still being able to achieve 0 down-time disaster scenario’s.
I hope this explains a bit why in some environments which have some similarity with the one I outlined above, you’ll see massive performance problems which grow exponentially with the increase of workload. As soon as the workload slows down or diminishes all problems disappear and no obvious trace of an issue can be found.
SAN options from Brocade like SDDQ and VOQ’s from Cisco can alleviate some of the most stressing problems but they are unable to resolve a architectural design flaw. It is up to the solution architects and system administrators to correctly design and configure these solution and not try to make shortcuts. At some stage this will come back and haunt you. A complete overhaul of the design and configuration when the solution is in production will give you many headaches.
Hope this helps
Kind regards,
Erwin van Londen
