
I get a huge amount of questions and nervous customers who tell me they see this counter increasing at an alarming rate and want to know if this is a problem or not.
The answer is yes and no. 🙂
That doesn’t help you much does it? Read on…..
In the Brocade world everything is ASIC based in the sense that every switch is using the same sort of ASIC’s throughout the entire chassis (unless you have different generations of blades in a chassis of course). These ASICS have ports either directly connected to a device you plug in or to a back-end interface in case of a director class chassis or high port-count switches.
Whenever an ASIC receives a frame the ingress port will decide to which egress port it needs to send this frame based on a routing table. Nothing new so far. To be able to do that it needs to know if that egress port is able to forward this frame to its destination. Therefore is that egress port shows it can send this frame the ingress-port will send it on and empty its buffer. When reading this you see there are a few things that come into play here.
As an example a short layout:
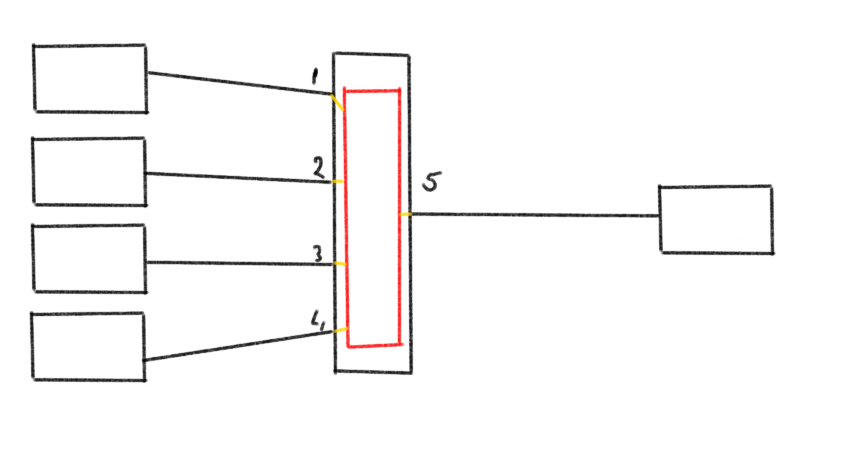 The left hand side are 4 initiators (HBA’s), the center part is a switch with the ASIC and the right hand side has the target (disk,array,tape)
The left hand side are 4 initiators (HBA’s), the center part is a switch with the ASIC and the right hand side has the target (disk,array,tape)
When traffic is generated from the host via port 1 towards the array on port 5 there is an even flow of available credits both from the HBA to port as well as from the switch port 5 to the array. (for credit flow mechanism please read here)
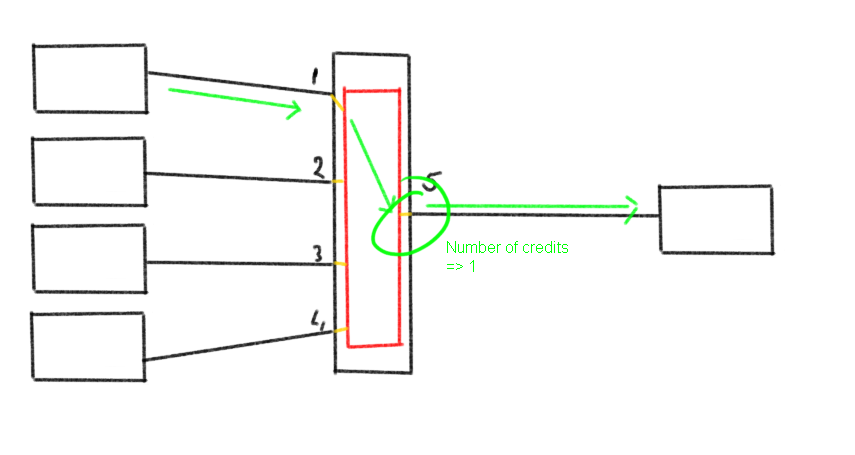 When multiple flows are sent from multiple hosts towards the same target you might see some credit shortage from the switchport towards the array at some spiky intervals.
When multiple flows are sent from multiple hosts towards the same target you might see some credit shortage from the switchport towards the array at some spiky intervals.
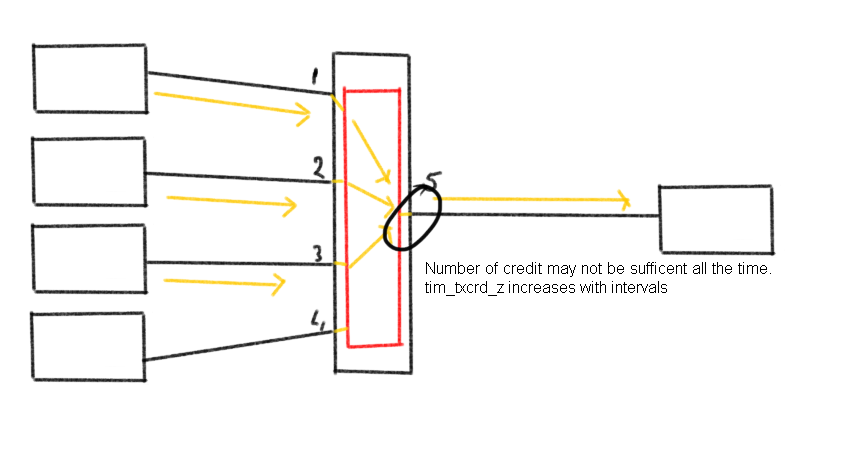 You will see that the tim_txcrd_z counter will ramp up during these busy times but it might not be nearly enough to notice any delay as all links might be fairly well utilized.
You will see that the tim_txcrd_z counter will ramp up during these busy times but it might not be nearly enough to notice any delay as all links might be fairly well utilized.
If however one or more additional flows are added which trip the ceiling of the link towards the array you will see that the duration of zero-credit status port 5 is in may cause performance problems and even IO errors if the frame hold time on the ingress port has been exceeded. (See the EHT post here how this works)
 “So why is this counter even important? ” you might ask. Well, unless you observe a performance drop this counter may not very indicative of a problem. It shows that at certain stages this link is used to an extent the edge-device is unable to handle the load.
“So why is this counter even important? ” you might ask. Well, unless you observe a performance drop this counter may not very indicative of a problem. It shows that at certain stages this link is used to an extent the edge-device is unable to handle the load.
In the above examples the direction of the flow is from HBA to array which indicates a high write workload. I could’ve also drawn the arrows the other way around when one or more HBA are doing a lot of reads. The same effect will then occur but you will then see that the tim_txcrd_z counter of the respective ports (1 to 4) will increase if that HBA/host is not able to offload the frames quick enough.
Given the fact the status of the buffer credit value is checked every 2.5us (microsecond) you’ll see that if a port is unable to send a frame due to a zero credit status for 1 ms (millisecond) this counter will already will already have accumulated 400 times. Just to provide some perspective if you extrapolate that to a hold time of 500ms (which is the hold time of a frame on core switches) it will flip to 200000 in a blink of an eye.
Cause of the problem
Design flaws
There are a few causes to this symptom and the first one is very often a design flaw or a misjudgment of traffic analysis/assumptions. If a storage environment is created with a high fan-in ratios (number of initiators to targets) you will see that, especially in a core-edge design, this counter will increase. I’ve seen ratios of 75 to 1 and most of the time administrators are oblivious of the problem they created.
This fault in design (or operational management) even compounds the problem is one or more initiators starts behaving as a slow drain device (see here and here).
Speed funnels
As I explained here when new and old technology is mixed, which in the case of shared storage environments is fairly often, you will see that the shared datapath of devices will slow down to the lowest common denominator. Obviously equipment with the fast speeds will still try to send and receive frames as quickly as possible and a stepping stone from 16G to 8G to 4G will in the end simply results in the a 4G data-rate. You can imagine that the tim_txcrd_z increases on all down-stream ports.
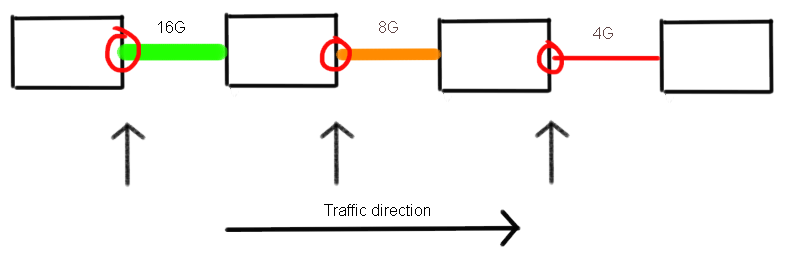 The ports circled in red will show an increase on tim_txcrd_z.
The ports circled in red will show an increase on tim_txcrd_z.
The other issue with “older” equipment is that besides the speed difference, the number of resources is also much smaller. You will often see that the number of buffers in old HBA’s is around 3 wheras newer HBA’s may be able to allocate 16 or 40. In virtual environments this may even be extended to 160.
Slow drain
The lack of buffers in older equipment in addition to the shortage of resources in servers or arrays may cause a certain device to behave as a slow-drain point in the fabric. I explained this over here. The existence of a slow drain device will cause all upstream ports to have problems propagating frames through a fabric. At some stage this might even lead to timeouts and frames might get dropped if their stage time crossed the hold-time threshold. (See EHT here and here.)
The er_tx_c3_timeout relation ship.
One thing you have to remember is that on Brocade architectures there are no egress buffers and as such frame will be discarded on the ingress side. If frames have been dropped you will see the er_tx_c3_timeout counter increase on the egress port to which these frames where originally routed. This means it is a proxy counter which accumulates to the sum of all frames discarded at one or more ingress port(s) but were routed to this egress port.
You will need to investigate links, switches and/or devices further downstream of that data path for issues I’ve described in the rotten apples series (here, here, here and here.)
I hope this explains a bit more around this tim_txcrd_z counter.
Regards,
Erwin
