
The piece of spinning Fe3O4 (ie rust) is by far the slowest piece of equipment in the IO stack. Heck, they didn’t invent SSD and Flash for nothing, right. To overcome the terrible latency, involved when a host system requests a block of data, there are numerous layers of software and hardware that try to reduce the impact of physical disk related drag.
One of the most important is using cache. Whether that is CPU L2/L3 cache, DRAM cache or some hardware buffering device in the host system or even huge caches in the storage subsystems. All these can, can will, be used by numerous layers of the IO stack as each cache-hit means it prevents fetching data from a disk. (As in intro into this post you might read one I’ve written over here which explains what happens where when a IO request reaches a disk.)
The IO stack on open-systems environments can be quite significant as the application requests data and the commands travel down and back up this stack.
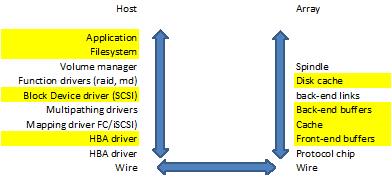
The problem with a fairly significant IO stack like the above is that the layers I highlighted may all be doing buffering and queuing. Especially on a busy system each layer will try to optimise the request in order to get the result back as soon as possible. Obviously the best IO request is the one which doesn’t exist at all and the application can retrieve the info from memory. You therefore see that applications such a databases are highly aggressive on caching and will utilise memory as much as it can. Response times are measured in nano- to low micro-seconds here. Everything that has to leave the CPU or memory will most certainly be measured in milliseconds which adds up significantly on performance bottlenecks.
If a request needs to leave the host system and requires data to be pulled from an external array the response times are totally depending on the capabilities and design of the storage network. Types of switches, arrays, connectivity options like Fibre-Channel and FCIP all have a significant influence on response time.
It is very often when performance problems are being escalated to the vendors the issue is actually not in the storage network at all but certain OS metrics are incorrectly interpreted.
When an application request is sent out on the wire in a fibre-channel SAN it is encapsulated in one or more FC frames, these frames are bundle in a so called uni-directional sequence which make up a so called Exchange. In short you could summary that a host IO is an exchange and the commands and data going back and forth are put in sequences. The sequences are then broken down into frames of around 2K. 2K is the maximum frame-size in a FC network. The SCSI behaviour right above the FC level does still apply basically meaning the SCSI layer sends a command, waits for data and a SCSI status response. If the command is a write command some more things need to happen on the array such as cache-slot allocations, threads need to be spawned to notify all sorts of processes to be able to offload that data from the incoming port, move to cache, copy it to a secondary cache boundary and offload it back to disks. If these processes have been done a so called XFER_RDY is sent back to the host basically telling it that the target is ready to receive either the full write IO or a portion (depending on available resources in the array of course). The host SCSI layer is then able to send that data to the array and after everything is received and committed in the array it will sent a a SCSI status frame with the result back. It is therefore fairly simple to monitor the performance from an array perspective as we can simply measure the difference between the time the command (read/write) comes in and the status frame goes back out. In the storage world we call this the so called “Exchange Completion Time“. That means that if we see a 3ms ECT from an array perspective but the host shows 50ms there is not much we can do to optimise that from an array perspecive.
Different operating systems measure and monitor the entire IO stack differently.
This is a capture (i know, just a single one is not much to go on but I was ensured the values were consistent) we received from a Solaris host showing a percieved performance problem where the customer sees a very high (~between 80 and 100ms) delay on IO requests:
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device 0.1 5.8 0.3 659.5 0.0 0.5 0.0 83.2 0 1 md/dbset/d50 0.1 7.6 0.2 328.4 0.4 0.1 53.7 8.1 0 1 c5t60xxxd0 0.1 8.3 0.2 330.2 0.5 0.1 59.5 7.8 1 1 c5t60xxxd0
Now, I’m not a performance guru so I may have misinterpreted the man pages but from what I’ve read the wsvc_t is the time the SCSI stack is waiting to do some stuff. The asvc_t is equivalent to the exchange completion time. So it seems the md device consisting of the two c5t6xxx devices has a high value because the underlying disks have a high service time. The actual completion time when a request leaves the system and the status has been received (asvc_t) is however very acceptable. This leads me to believe that there is some buffering going on in the device driver queuing mechanism but that is not something I could figure out from the limited set of info I could retrieve fro this system.
The storage infrastructure also had a synchronous replication solution on the back of it hence the fairly low response time (relatively speaking) of ~8ms. It basically means that the write-request plus data was received from the host, then copied to the remote array which was 10KM away, over there it has to be put into both cache boundaries, that status will then be sent back to the primary array after which this one can inform the host the IO is completed.
Looking at the numbers it seems that the IO’s from the individual disks is not the problem but more the queuing back to the md device driver informing that the single write IO being spawned over two physical disks has been completed. I would like to see an hypothesis from a Solaris/Unix expert on this.
I hope this sheds some light on why a perceived latency is not always SAN or array related.
If you want to know more on performance tuning you may want to check out Brendan Gregg’s blog where he posts a huge amount of extremely geek level info regarding this topic.
3 of his books I would highly recommend:
[amazon template=iframe image2&asin=0133390098] [amazon template=iframe image2&asin=0132091518] [amazon template=iframe image2&asin=0131568191]
Regards
Erwin

Suppose that there is need for checking HBA queue depth
Hi Yury,
That may well be the case. We haven’t been given much info on this system when I wrote this article. max_execution_throttle was not set so I don’t know what the default is on this system.