You might have heard about it, maybe not, but it can become a problem if it stings you: “A stuck VC” . So first of all what is it? Well, basically it is a virtual channel on an E-port or back-end port that has depleted the number of credits on one or more Virtual Channels of that port.
Ok, lets have a look on how a frame might traverse a switch from one port to another. In the below picture you can see a schematic overview of how a frame going into slot 1 traverses via slot 5 to slot 12 and exit the switch over there.
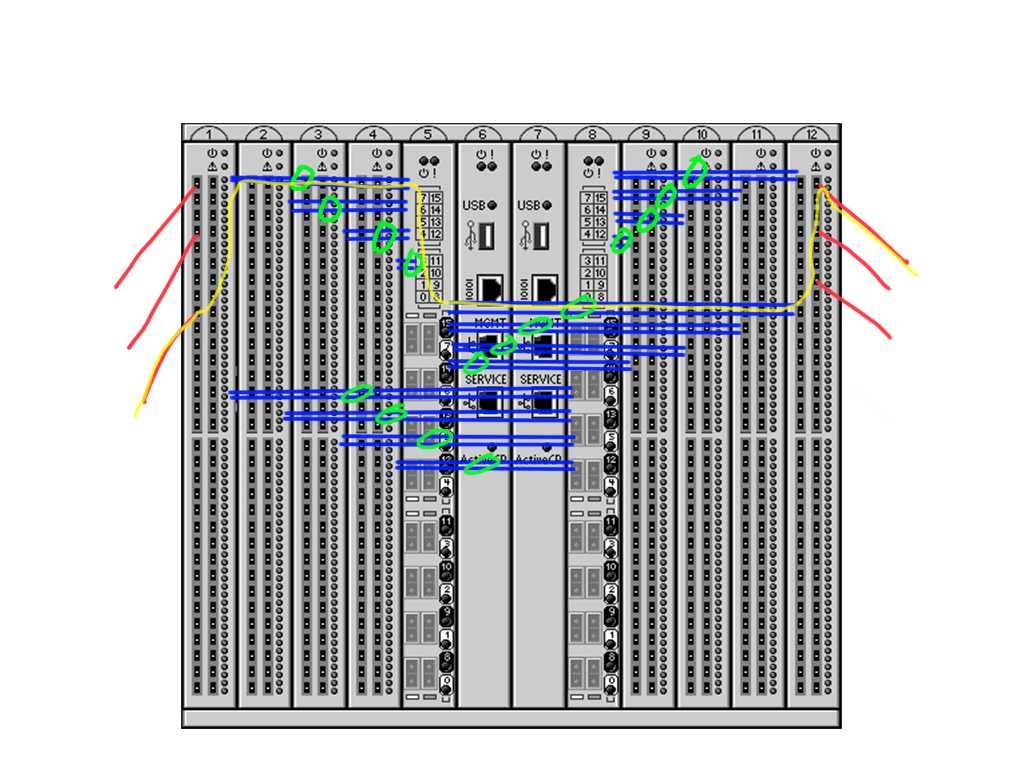
The red line represent a front-end port (ie a port where you actually plug a cable in) and the blue lines show the links between the slots traversing the chassis backplane. Based on the type of switch and the port count of the blade these back-end links may be trunked (green circles) in 2 or 4 port-members or non at all. The picture is just an example.
When looking somewhat deeper into each of these back-end links you will see that they are divided into multiple virtual channels. These work similar as on front-end ISL’s. Based on that VC and a Brocade proprietary algorithm the frames are prepended with a, so called “shim header” and then mapped onto these virtual channels by the port of the sending ASIC and are then transferred to either one of the core-blades or directly to the egress port if that egress port is on the same ASIC as the ingress port. The shim header is a switch internal header which is abused for all sorts of switching logic however I haven’t been able to obtain more info around this. You will never see this leave a switch though so trying to capture this on a FC analyzer will bear no fruit.
The traffic flow algorithm itself works similar as on front-end E-ports in the sense that the sending port needs to have a credit available to be able to send a frame for that specific VC where the frame is mapped on. Normal FC behaviour. The back-end ports also observe the same timing configuration as the front-end ports and hence these can also drop frames in case of timeouts, corrupt routing tables etc. This also means they they are susceptible to the same error scenario’s. Link issues as I described here, here and here will cause either physical link failures like synchronization errors or corrupt bit-streams where the encoding/decoding layer is no longer able to differentiate between 0 and 1. This can cause VC_RDY’s to get lost hence causing credit depletion. A second issue is that errors on a front-end side might propagate to the back-end as well. Even though it does not corrupt the bitstream it may introduce certain very tiny timing problems which could also cause VC_RDY’s to get lost.
Detection and notification
FOS has always monitored traffic flow however depending on the FOS version combined with the ASIC it was able to detect and recover from such credit issues or not.
FOS version prior to 6.3.1a:
- On FE links when traffic is had stopped for over 2 seconds and a frame was waiting to be sent over that port plus there was no credit left the port would issue a LR (Link Reset) hence clearing all buffers and resetting the credit to the login value. (The value that was negotiated upon FLOGI.
- A CDR-5021 or C2-5021 (Condor and Condor-2 respectively) event would be logged in the RAS log.
On back-end links the behaviour was similar.
- The detection was not possible on an individual VC so only when no traffic was seen for 2 seconds on the entire port a LR was sent which meant that the port would clear ALL buffers of all VC’s on that particular port.
- A CDR/C2-5021 event would be logged
- No partial credit loss could be detected so even though the credit was not stuck at zero a certain performance implication could be noticeable.
With FOS 6.4.0 some new features where implemented which where also back-ported to 6.3.2 and 6.3.1a.
To address observations like devices showing high-latencies due to returning R_RDY very slow or not at all and therefore causing credit back-pressure further down-stream of the device Brocade introduced the following features:
- Port fencing. This allowed the switch to shut down a port when it obverses errors beyond a configurable threshold.
- Edge-Hold-Time. This allowed the switch to drop frames at an F-port sooner than on a E-port. This prevented the ISL’s to become constantly saturated due to a credit shortage caused by back-pressure of another device.
- Introduction of bottleneck detection. This provided the ability to measure and detect latencies. In 6.41 and 6.42 there were additional options added.
On the back-end side the detection logic was improved to be able to detect a single lost credit plus the RAS log entries were changed to show which VC and how many credits where lost. The back-end link was constantly monitored for lack of traffic for 2 seconds. It then compared the actual credits on each VC with the expected value and if that was not the same it would generate a a CDR/C2-5021 message as it did with older FOS versions.
FOS 6.3.2b, 6.4.2 and 7.0.0 added more enhancements.
- First the event logging was adjusted and moved to the normal eventlog with CDR/C2/C3-1012 messages and it could be propagated to SNMP or syslog recipients.
- Detection of a single lost credit and the logging of these values where added.
These versions used the same 2-second timeframe to detect the loss but also could recover automatically by sending an LR. A CDR/C2/C3-1014 event was logged to record the LR. One additional feature was added where an entire blade could be faulted in case the port-reset did not work and the credit value would still remain at 0. The bottleneckmon command was introduced to be able to configure the recovery options. The most often used option was “bottleneckmon –cfgcredittools -intport -recover onLrOnly“.
FOS 6.4.3 and 7.01b
Decoupled the latency and congestion notification. This was done to be able to differentiate between misbehaving devices or simply very high link utilization.
The Edge-Hold-time was adjusted to provide a 3 pre-set value (80,220 and 500ms) which was further enhanced in FOS 7.0.2 where the value could be entered manually between 80ms and 500ms.
FOS 6.4.3a and 7.0.2
A new manual check mechanism was introduced via the bottleneckmon –cfgcredittools -intport -check <slot>/<port>,<VC> command. As of these versions the detection and recovery logic was further enhanced and provided protection for complete loss of credit on a back-end link. FOS will automatically invoke the “manual” check when a frame was dropped due to a timeout and will issue a LR if it is determined the port has indeed observed a complete loss of credit.
These versions also introduced the serdestunemode –auto<enable,disable,reset,show> commands. This feature monitors physical aspects of a back-end serdes chip and can adjust gain and equalization in order to obtain a better signal receiver quality and thus reducing the chance such an error has on back-end frame and credit flow. ) Be aware that although this can improve the back-end link characteristics it doesn not 100% exclude such issues from occurring.)
Lastly as of these version it is now also possible to manually issue a LR on any back-end port. This is however a last resort and will only need to be executed upon request of your OEM support-engineer or Brocade. A C2-1014 event will be logged if such an LR occurs.
Change in CLI
As os FOS 7.2 a new CLI command is introduced to separate the credit-recovery from bottleneck monitoring.
creditrecovmode
creditrecovmode –cfg [off | onLrOnly | onLrThresh] [-lrthreshold threshold]
-fault [edgeblade | coreblade | edgecoreblade]
creditrecovmode –check [slot/]blade_port,VC
creditrecovmode –fe_crdloss [off | on]
creditrecovmode –linkreset [slot/]blade_port
creditrecovmode –show
creditrecovmode –help
This command will replace the functionality of the bottleneckmon –cfgcredittools part in FOS 7.3.
Failure modes
If an attempt to recover a credit fails for whatever reason the switch is able to fault an edge or core-blade or both. This might sound terrifying from a redundancy perspective however be aware that if all best practises are followed every host and target should be able to proceed on their redundant paths. This is more effective than hosts needing to recover and re-issue entire IO requests over and over again. See here for more info on this.
To enable this use the -fault <edgeblade|coreblade|edgecoreblade> parameters.
FOS 7.2.1b and 7.3.0
These versions introduced an automatic creditloss detection mechanism for individual VC’s on a front-end ISL port. It triggers when a TX timeout is seen and will issue a LR when a complete credit-loss is detected on one of the VC’s.
Triggers
Be aware that in any of the previously mentioned FOS versions the recovery mechanisms only work when a frame-drop is seen due to a timeout and a loss of credit on a port or VC has been detected. If in any way a frame is dropped due to congestion there will be no action at all. In any case of congestion, irrespective of front-end or back-end ports, it is most likely due to a design mistake and some review is required. Workload needs to be moved to other parts of the fabric or more dispersed over multiple ports.
Preventive measures
There is no solid method to fully prevent this phenomenon from happening however the chances can be reduced by observing front-end issues on the physical layer, and back-end problems when it comes to serdes failures. In almost all cases using the latest available FOS codes will prevent serdes issues as numerous changes have been made to adjust these gain/equalization values in order to maintain an optimal synchronization pattern. In the very unlikely event that a stuck-VC phenomenon occurs the recovery options in later FOS codes are sufficient and will almost always recover the ports and VC’s.
Even though it might have an impact from a performance perspective it can NEVER be the cause of a host/application outage. If your host/application suffers from this phenomenon you should put serious questions questionmarks behind the redundancy and design of the solution.
I hope this explains the issue a bit.
Kind regards,
Erwin

Thank you for such a good summary of all the development in this area in the last 3-4 years!
The only thing that is missing is … just a little bit of spell-checking 🙂
🙂