I’ve been writing about troubleshooting issues for a while now and one of the things that is very difficult and most time consuming is correlating events between host systems, switches and storage arrays in the even of storage related errors. My advice has always been the same. Hook everything up to NTP systems, make sure that time and date settings, including time-zones and DST settings do fall within the drift values of the NTP client and that little nifty piece of software will make sure time is equal on all systems. (See below how to accomplish this.)
There are however some issues when this is not fully followed through and virtual switches are used.
The Brocade and Cisco switches will distribute time configuration settings through the fabric. The configuration of a principle switch and/or FCS switch will be send to all switches in each fabric. Let me make this clear !!! in each FABRIC. !!!!
The clock is however kept on the chassis. There is ONE NTP process or local system clock that keeps the time for the entire chassis. This means that if you have different settings on each virtual switch either pointing at different NTP servers or different time-zone settings or anything else that conflicts with reality you’re in for a problem and you will see very weird results.
As an example below check out the different chassis where different switches are principles and some switches are fabric principles and others are not. (pardon my drawing)
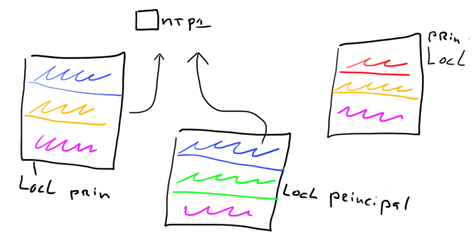
Fabric Blue spans chassis 1 and 2, fabric Orange on chassis 1 and 3, fabric Green on chassis 2 and Fabric Red on chassis 3. Only the Orange fabric via chassis 1 and the Blue fabric via chassis 2 are configured to look at the NTP server on top.
As you can see given the fact the role of fabric principle in addition to the fact some virtual switches are configured via LOCL the are many conflicts when time needs to be set. Each virtual switch can update the time, if it is fabric principle, and conflict with virtual switches on other chassis who are hooked up to NTP or not. These results will be totally unpredictable. Moreover eventlogs will be more or less useless when granularity is required such as in portlogdump, fabriclog and others.
In order to keep time consistency across all switches in all fabric do the following:
 Configure 1 switch in the chassis to use an external NTP time-source. To make this easy use the defaults switch. Leave every other virtual switch in the chassis configure with LOCL.
Configure 1 switch in the chassis to use an external NTP time-source. To make this easy use the defaults switch. Leave every other virtual switch in the chassis configure with LOCL.
The principle switches across each of the fabrics will make sure they use the chassis time and distribute this across the fabrics. Since those virtual switches have the same time as their local default switch also obtains the time from the same timeserver there will be no adjustment. In the above picture you can see that the purple fabric consists of 3 virtual switches all hooked up to the NTP server and as such determine the correct time for the entire chassis. The other virtual switches who are principle will pick up this time and distribute that to their peers.
If you have edge switches hanging off these chassis core-switches it doesn’t really matter if you configure NTP on these as long as you make sure the virtual switches on the chassis keeps the fabric principle role. (Use the “fabricprinciple” command for this.)
 In the above example the edge switch in the Red fabric retains its time from the Red virtual switch in chassis #3. If the fabric-principle role changes to this edge switch you need to configure that switch to use the same NTP server as the 3 chassis switches. Atherwise you might run into the same discrepancy as described above.
In the above example the edge switch in the Red fabric retains its time from the Red virtual switch in chassis #3. If the fabric-principle role changes to this edge switch you need to configure that switch to use the same NTP server as the 3 chassis switches. Atherwise you might run into the same discrepancy as described above.
Regards,
Erwin van Londen

Hi Erwin, thanks, that’s a good reading!
Clock sync is really essential when troubleshooting a complex issue.
I once had to help people finding the problem, where each component was supported by a different support partner: AIX host, HP disk array, EMC multipathing and CISCO SAN – what a nightmare environment to build and maintain! And BTW everything was hooked to NTP, except disk array SVP, but its time difference (like 57 minutes or something like this) was already carefully recorded. So the email thread when I’ve got it looked like this:
IBM: ERRPT shows FC errors and resets at 7PM. What do you see at this time?
EMC: yes we see this in the PowerPath logs.
HP: well we see some SCSI reserve conflicts, but we cant tell why they happen…
CISCO: we don’t see anything at all!!!
Others: ??????
It was the first in my life troubleshooting exercise with CISCO and I was surprised to discover that they log everything using GMT, so SAN guys were looking at the much later point of time in fact… Also, at the end of the end, CISCO wasn’t found guilty 😉