Fibre-Channel is still the predominant transport protocol for storage related data transmission. And rightfully so. Over the past +-two decades it has proven to be very efficient and extremely reliable in moving channel based data transmissions between initiators and targets. The reliability is due to the fact the underlying infrastructure is almost bulletproof. Fibre-Channel requires very high quality hardware as per FC-PI standard and a BER (Bit Error Rate) of less than 10^12 is not tolerated. What Fibre-Channel lacks though is an method of detection and notification to and from hosts if a path to a device is below the required tolerance levels which can cause frames to be dropped without a host to be able to adjust its behaviour on that path. Fibre-Channel relies on upper level protocols (like SCSI) to re-submit the command and that’s about it. When FC was introduced to the market back in the late 90’s, many vendors already had multipath software which could correlate multiple paths to the same LUN into one and in case one path failed it could switch over to the other. Numerous iterations further down the road nothing really exciting has been developed in that area. As per the nature of the chosen class-of-service (3) for the majority of todays FC implementations there is no error recovery done in an FC environment. As per my previous post you’ve seen that MPIO software is also NOT designed to act on and recover failed IO’s. Only in certain circumstances it will fail a path in a way that all new IO’s will be directed to one or more of the remaining paths to that LUN. The crux of the problem is that if any part of the infrastructure is less than what is required from a quality perspective and there is nothing on the host level that actively reacts on these kind of errors you will end up with a very poor performing storage infrastructure. Not only on the host that is active on that path but a fair chance exists other hosts will have the same or similar problems. (see the series of Rotten Apples in previous posts.)
So what is my proposal. Hosts should become more aware of the end-to-end error ratio of paths from their initiators to the targets and back. This results in a view where hosts (or applications) can make a judgement call of which path it can send an IO so the chances of an error are most slim. So how does this need to work. I is all about creating an inventory of least-error-paths. For this to be accomplished we need a way of getting this info to the respective hosts. Basically there are two ways of doing this. 1. Either create a central database which receives updates from each individual switch in the fabric and the host needs to query that database and correlate that with the FSPF (Fabric Shortest Path First) info in order to be able to sort things out or, and this would be my preferred way, we introduce a new ELS frame which can hold all counters currently specified in the LESB (Link Error Status Block) plus some more for future use or vendor specific info. I call this the Error Reporting with Integrated Notification frame. This frame is sent by the initiator to the target over all paths it has at its disposal. Each ingress port (RX port on each switch) which this frame traverses and increment the counters with its own values. When the target receives the frames it flips the SID and DID and send it back to the host. Given the fact this frame is still part of the same FC exchange it will also traverse the same path back so an accurate total error count of that path can be created.
Both options would enable each host of analyzing the overall error count on each path from HBA to target for each lun it has. The problem with option 1 is that the size of the database will increase exponentially proportional with the number of ports and paths and this might become such a huge size that it cannot live inside the fabric anymore and thus needs to be updated in an external management tool. This then has the disadvantage that host are depending on OOB network restrictions and security implications in addition to interop problematic issues. It also has the problem that path errors can be bursty depending on load and/or fabric behaviour. This management application will need to poll these switches for each individual port which will cause an additional load on the processors on each switch even while not necessary. Furthermore it is highly unreliable when the fabric is seeing a fair amount of changes which by default causes re-routing to occur and thus renders a calculation done by the host one minute ago, totally useless.
Option two has the advantage that there is one uniform methodology which is distributed on each initiator, target and path. It therefore has no impact on any switch and/or external management application and is also not relying on network (TCP/IP) related security restrictions, Ethernet boundaries caused by VLANS etc or any other external factors that could influence the operation.
The challenge is however that today there is no ASIC that supports this logic and even if I could get the proposal accepted by T11 it’ll take a while before this is enabled in hardware. In the meantime the ELS frame could be sent to the processor of the switch which in turn does the error count modification in the frame payload, CRC recalculation and other things required. Once more the bottleneck of this method will become the capability of the CPU of that particular switch especially when you have many high port-count blades installed . Until the ASICs are able to do this on the fly in hardware there will be less granularity from a timing perspective since each ELS frame will need to be sent to the CPU. To prevent the CPU from being flogged by all these update and pull requests in the transitional period there is an option to either extend the PLOGI to check if all ports in the path are able to support this frame in hardware or use this new ELS with a special “inventory bit” to determine the capabilities. If any port in the part does not not support the ELS frame it will flick it to 0. This allows the timing interval of each ELS frame to be inline with the capabilities of the end-to-end path. You can imagine that if all ports are able to do this in hardware you can achieve a much finer granularity on timing and hosts can respond much quicker on errors. If any port does not support the new ELS frame the timing can be adjusted to fall in between the E_D_TOV and R_A_TOV values (in general 2 and 10 seconds). The CPU’s on the switches are fairly capable to handle this. This is still much better than any external method of collecting fibre-channel port errors and having an out-of-band query and policy method. Another benefit is that there is a standard method of collecting and distributing the end-to-end path errors so even in multi-vendor environments it is not tied to a single management platform.
So lets look at an example.
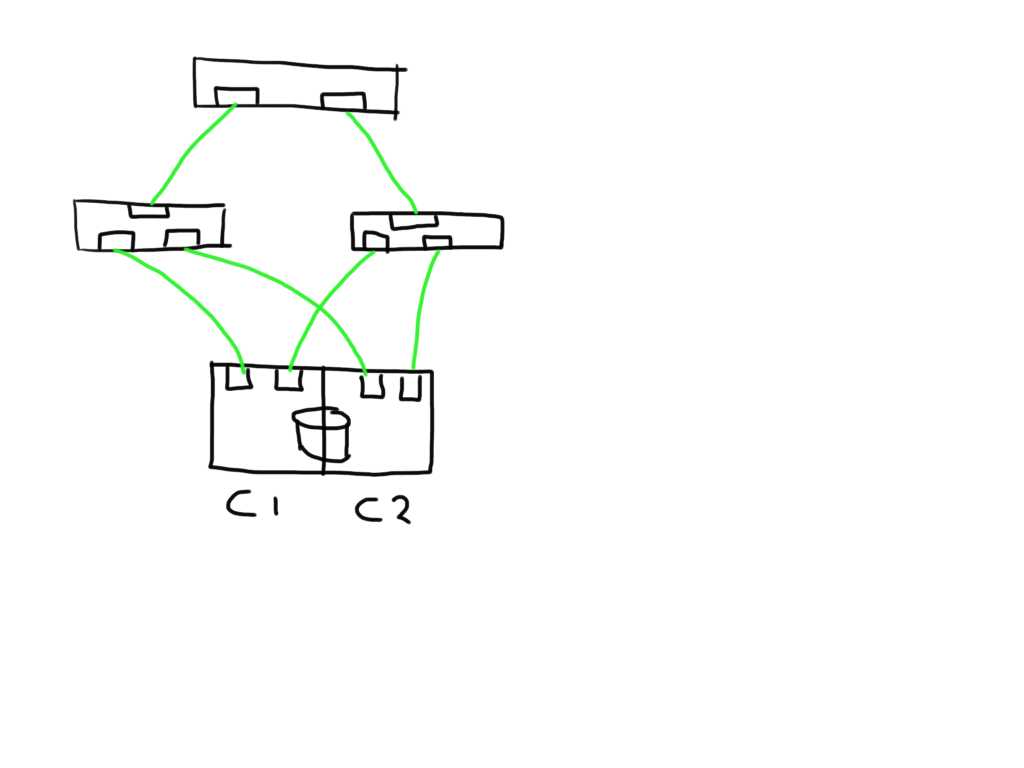 This shows a very simplistic SAN infrastructure where one host has 4 paths over two initiators to 2 storage ports each. All ports seem to be in tip-top shape.
This shows a very simplistic SAN infrastructure where one host has 4 paths over two initiators to 2 storage ports each. All ports seem to be in tip-top shape.
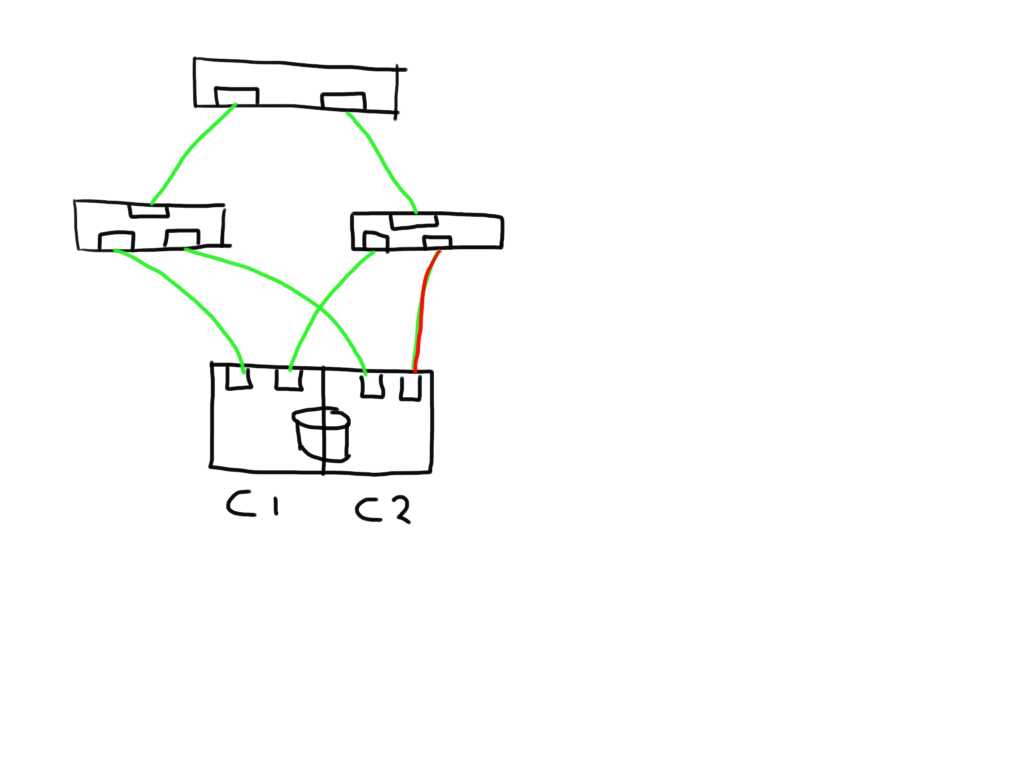 If one link (in this case between the switch and the storage controller) is observing errors (in any direction) the new ELS frame would increment that particular LESB counter value and the result would enable the host to detect the increase in any of the counters on that particular path. Depending on the policies of the operating system or application it could direct the MPIO software to mark that path failed and to remove it from the IO path list.
If one link (in this case between the switch and the storage controller) is observing errors (in any direction) the new ELS frame would increment that particular LESB counter value and the result would enable the host to detect the increase in any of the counters on that particular path. Depending on the policies of the operating system or application it could direct the MPIO software to mark that path failed and to remove it from the IO path list.
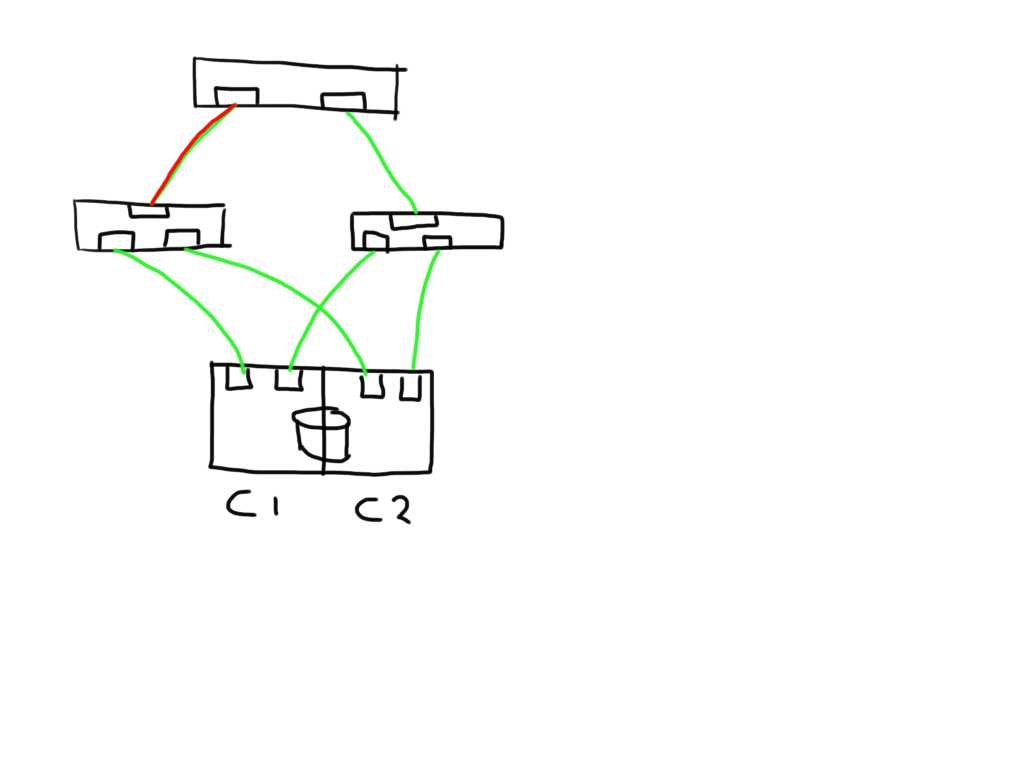
Similarly if a link shows errors between an initiator and switch it will mark 2 paths as bad and has the option to mark these both as failed.
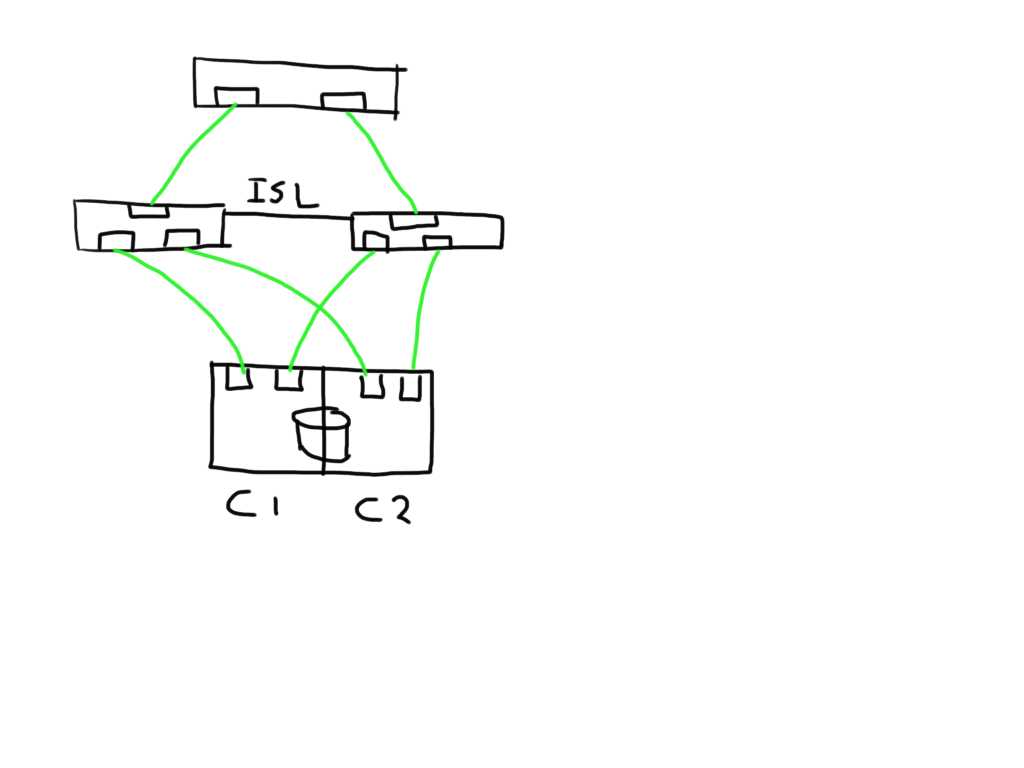
 If you have a meshed fabric the number of paths exponentially grow with each switch and ISL you add. The below show the same structure but because an ISL has been added between the switches the number of potential paths between the host and LUN now grows to 8
If you have a meshed fabric the number of paths exponentially grow with each switch and ISL you add. The below show the same structure but because an ISL has been added between the switches the number of potential paths between the host and LUN now grows to 8
 This means that if one of the links is bad the number of potential bad paths also duplicates.
This means that if one of the links is bad the number of potential bad paths also duplicates.
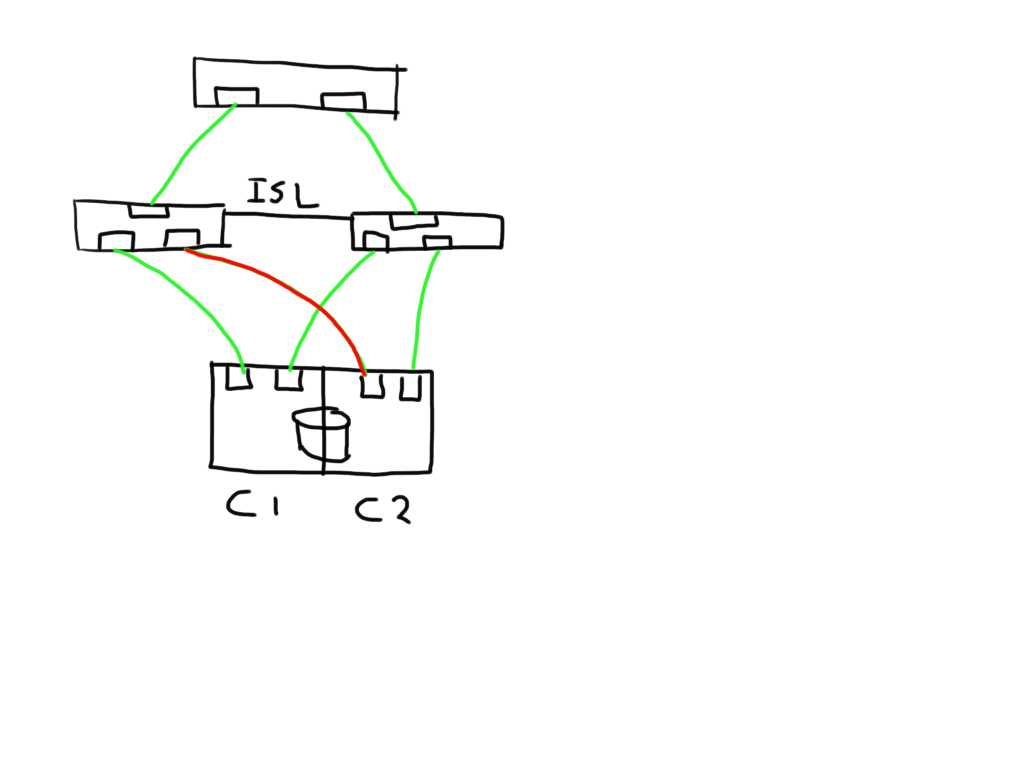 In this case the paths from both initiators on this bad link are marked faulty and can be removed from the target list by the MPIOsoftware.
In this case the paths from both initiators on this bad link are marked faulty and can be removed from the target list by the MPIOsoftware.
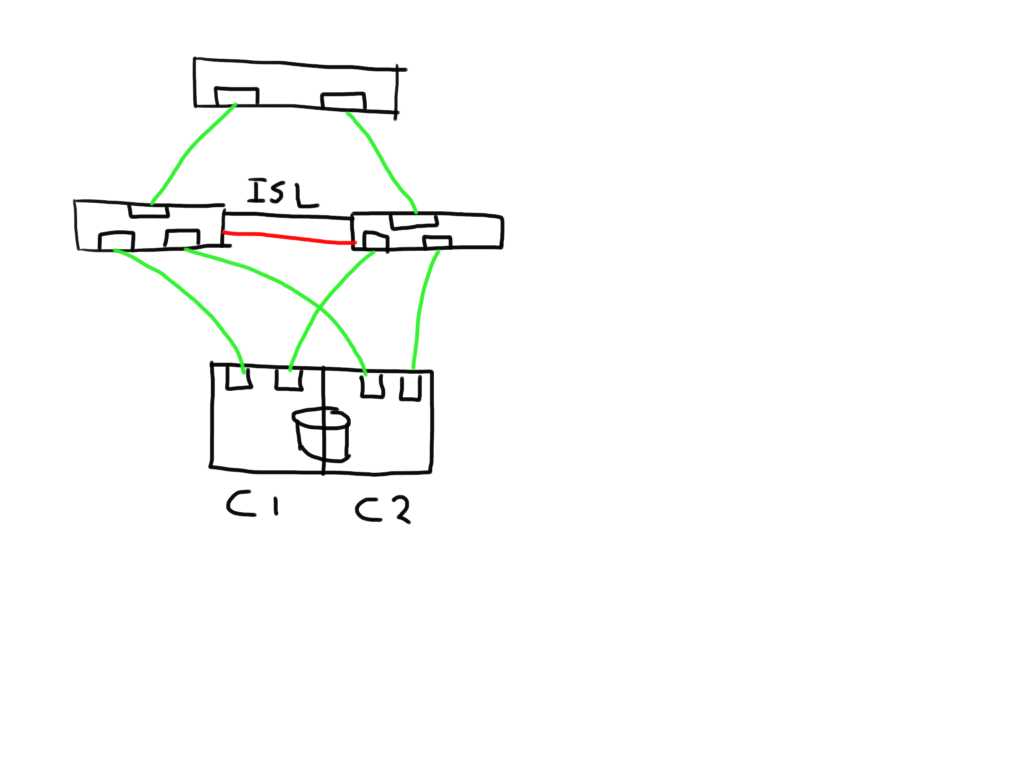 The fun really starts with the unexpected. Lets say you add an additional ISL and for some reason this one is bad. The additional ISL does not add new paths to the path-list on the host since this is transparent and is hidden by the fabric. Frames will just traverse one or the other irrespective of which patch is chosen by the host software. Obviously, since the ELS is just a normal frame, the error counters in the ELS might be skewed based on which of the two ISL’s it has been sent. Depending on the architecture of the switch you’ll have two options, either the ASIC accumulates all counters for both ports into one and add these onto the already existing counters, or you can use a divisional factor where the ASIC sums up all counters of the ISL’s and divides them by the number of ISL’s. The same can be done for trunks(brocade) / portchannels(Cisco). Given the fact that currently most the counters are used in 32bit transmission words the first option is likely to cause the counters to wrap very quickly. The second advantage of a divisional factor is that there will be a consistent averaging across all paths in case you have a larger meshed fabric and thus it will provide a more accurate feedback to the host.
The fun really starts with the unexpected. Lets say you add an additional ISL and for some reason this one is bad. The additional ISL does not add new paths to the path-list on the host since this is transparent and is hidden by the fabric. Frames will just traverse one or the other irrespective of which patch is chosen by the host software. Obviously, since the ELS is just a normal frame, the error counters in the ELS might be skewed based on which of the two ISL’s it has been sent. Depending on the architecture of the switch you’ll have two options, either the ASIC accumulates all counters for both ports into one and add these onto the already existing counters, or you can use a divisional factor where the ASIC sums up all counters of the ISL’s and divides them by the number of ISL’s. The same can be done for trunks(brocade) / portchannels(Cisco). Given the fact that currently most the counters are used in 32bit transmission words the first option is likely to cause the counters to wrap very quickly. The second advantage of a divisional factor is that there will be a consistent averaging across all paths in case you have a larger meshed fabric and thus it will provide a more accurate feedback to the host.
I’m working out the details w.r.t. the internals of the ELS frame itself and which bits to use in which position.
This all should make Fibre-Channel in combination with intelligent host-based software an even more robust protocol for storage based data-transmissions.
Let me know what you think. Any comments, suggestions and remarks are highly appreciated.
Cheers
Erwin
