I’ve been focusing on the implications of physical issues a lot in my posts over the last ~2 years. What I haven’t touched on is logical performance boundaries which also cause extreme grief in many storage infrastructures which lead to performance problems, IO errors, data-corruption and other nasty stuff you do not want to see in your storage network.

Speed
There is a well known saying that speed is reduced based upon the slowest entity in a certain environment. You can put 10 Formula 1 cars on a race track and they all drive with blazing speed. If you add 10 Go-Carts on that same track in the end the F1 cars will need to reduce their speed to avoid accidents and thus you will no gain benefit. When it comes to the speed of light is is the same comparison. Shine it through a vacuum and it travels at around 300.000KM/s. Add the refraction-index of a glass cable and you’ll only get around 2/3rd of that.
The same is true for a storage network (or networks in general).
The case
Last week I had one of those cases where a customer shared links in a production and test environment because of logistical reasons. Storage hardware in one room, prod-servers in another and test/dev in the room next to that.
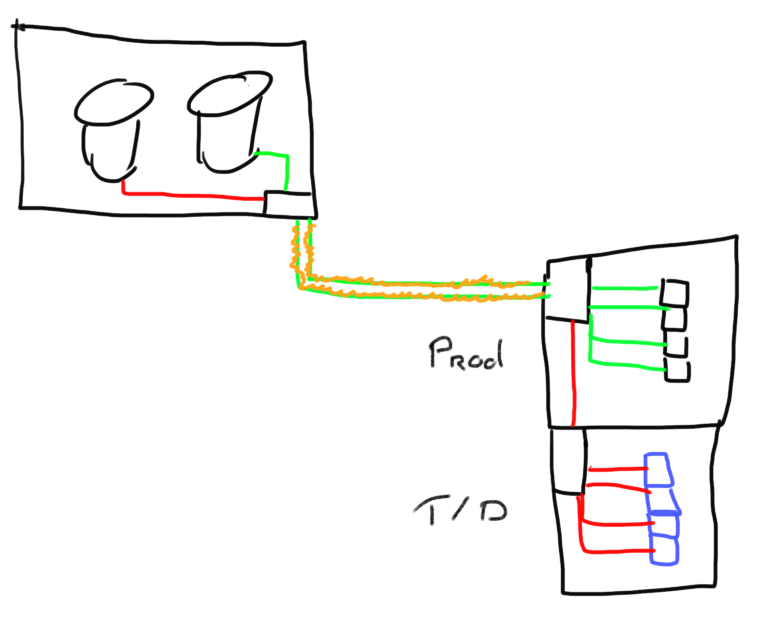
The green lines depict the links from the production server and storage systems. The red lines indicate the older links connecting to slower speed equipment. The wiggly orange lines show the shared link between the storage and production room.
Obviously from a cost perspective it was pretty beneficial to use the ISL links from the production environment to the storage system instead of adding a separate network for T/D. There had been more performance issues in the past however the reshaping of IO profiles and workload schedules more or less alleviated (or better said obfuscated) the real underlying problem. The problem became more severe when more test & dev activities were done due to new and changed business requirements. Applications where revamped, developers and test engineers increased the utilization of T/D environment by spinning up new and more virtual machines etc.
Cost-reduction vs Performance vs Functionality.
There is a famous triangle which outlines that you cannot have all three at the same time. If you increase functionality it’ll cost money and most likely performance will suffer. If you want to decrease cost you will need to give in on certain features, functions and/or performance expectations. Since the activities mentioned previously did not take performance or features into account and just wanted to use the functionality of having systems quickly deployed there was no investment on the hardware side so older kit was used to hook up this T/D and use the ISL’s between the switch in the storage room and the the one in the prod-room.
Performance bottleneck
Normally you’ll see a performance bottleneck in the centre of a edge-core-edge fabric (which is a bad design anyway) most often due to under-provisioning of ISL’s which cause congestion. In this case however the bottleneck was not the link between the storage and production rooms but is was the victim of the low bandwidth and higher latency of the older equipment in the T/D environment.
The extensive use of virtual machines in the T/D environment ensured maximum flexibility but what wasn’t taken into account is that hypervisors are extremely good in caching. They try to maximize memory utilization to keep as much as possible of a VM in memory. When the VM shuts down it’ll flush that memory with pleasure back to disk to be able to allocate that memory to other running VM’s. This goes hand-in-hand with very high IO chunk-sizes which will significantly use bandwidth. Since Fibre-Channel is using a buffer-to-buffer credit mechanism you can imagine that when a gigabyte or more of data (the cached content of a VM) is pushed to a somewhat older storage array there will be a significant pressure on the storage system on the other side. If it becomes to busy it will just elongate offloading data from the FCP stack which causes credit back-pressure onto the switchport. Basically the switch does not receive an R_RDY (Receiver Ready) primitive to allow it to send another frame. If this goes on long enough even the ISL’s will observe the same phenomenon. The switch in the production room does not get these primitives from the remote side in order to send a frame. Let me be clear : “A frame” (with a capital A) . This is irrespective of the source of that frame basically meaning that every system, whether being dev, test or production and irrespective of application, sits on the backseat waiting to be able to traverse that ISL.
You can imagine that the more busy the T/D systems push their storage the more severe this problem becomes and eventually will lead to timeouts, framedrops and IO retries.
The solution
There are basically two solutions to this. An expensive one or a smart one. I chose the latter. I’m not a sales commission. 🙂
The expensive one obviously would be to physically separate the two environments but that would include purchasing new switches, replacing HBA’s or SFP due to an revision incompatibility etc.
What I advised is to utilize the virtual fabrics feature to logically separate the two environments into their own logical fabric. The only physical change was adding a new ISL and some re-cabling to isolate the ISL’s onto their own ASIC’s to prevent further sharing of links inside the switches. This prevented not only isolation of traffic but also segregation of fabric services. This will prevent potential firmware/driver/OS issues having an adverse effect on the production systems in the event they conflict with processes like fabric-controller, nameserver etc. An additional benefit was that the administrators of the T/D environment now can make their own changes like zoning and generic port configurations without influencing (or even having access) to production systems. This provides stability and piece-of-mind.
As you can see there is more than meets the eye when designing a fabric-infrastructure and trying to incorporate a multipurpose environment onto a single physical infrastructure.
Cheers, Erwin
PS. as always, pardon my drawing skills.

Hi Erwin,
Another solution could be TI zones… Maybe in your next post?
Regards,
Gael
Hi Gael,
From a technical flow control perspective this would have been an option however I also wanted to segregate the functional part so that from an administrative point of view there was much more flexibility and less room for error. The concept of TI zones (which in essence is just a routing adjustment) may become even dangerous if it not set-up and administered correctly.
Food for thought indeed. 🙂
Regards,
Erwin